 Employee Experience
Employee Experience De klassieke benadering van Web 3.0


Het is tijd om de droom van het semantic web te verwezenlijken. Dat is de mening van grondlegger van het web Sir Tim Berners-Lee. Volgens hem liggen de bouwstenen klaar voor het maken van intelligente semantische webapplicaties. Die bouwstenen maken deel uit van wat wel bekend staat als de klassieke benadering van Web 3.0. Wat houdt die benadering precies in?
Een tijdje geleden schreef ik voor dit blog over de betekenis van Web 3.0 en het semantic web. In dat artikel kwam naar voren dat we het huidige web kunnen zien als een web van documenten. Het semantic web daarentegen is een web van entiteiten. Documenten zijn de webpagina’s, entiteiten zijn de onderwerpen in webpagina’s: personen, landen, bedrijven, muziek, reizen, gebouwen, in feite alle onderwerpen die je maar kunt verzinnen. Precies de dingen die voor mensen interessant zijn dus. Als computers entiteiten en de samenhang tussen entiteiten beter kunnen begrijpen, dan kunnen ze ons beter begrijpen.
De ideeën voor een semantic bestaan al enige tijd. In 1994 sprak Berners-Lee er al over. Toen was nog niet duidelijk hoe men dit kon  realiseren. In mijn vorige artikel beschreef ik 2 mogelijkheden van hoe zo’n semantic web tot stand zou kunnen komen: de bottom-up en de top-down benadering. De bottom-up benadering zegt: “voorzie alle webpagina’s in het internet van extra informatie over entiteiten zodat webapplicaties kunnen begrijpen waarover die pagina’s gaan”. De top-down benadering daarentegen wil juist webapplicaties zo intelligent maken dat ze zelfstandig de entiteiten in webpagina’s begrijpen. De webpagina’s hoeven dan dus niet van extra informatie te worden voorzien.
realiseren. In mijn vorige artikel beschreef ik 2 mogelijkheden van hoe zo’n semantic web tot stand zou kunnen komen: de bottom-up en de top-down benadering. De bottom-up benadering zegt: “voorzie alle webpagina’s in het internet van extra informatie over entiteiten zodat webapplicaties kunnen begrijpen waarover die pagina’s gaan”. De top-down benadering daarentegen wil juist webapplicaties zo intelligent maken dat ze zelfstandig de entiteiten in webpagina’s begrijpen. De webpagina’s hoeven dan dus niet van extra informatie te worden voorzien.
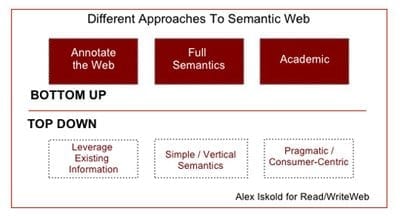
Dit artikel gaat dieper in op de bottom-up benadering, ook wel klassieke benadering genoemd omdat hij al zo lang bestaat. Hoe zit die in elkaar? Wat is er inmiddels mee mogelijk? Welke moeilijkheden moeten nog worden overwonnen?
Het klassieke semantic web bestaat uit bouwstenen met exotische namen als RDF, OWL, GRDDL en SPARQL.
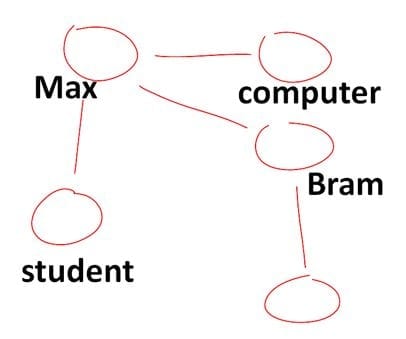
RDF is het belangrijkste concept. Het staat voor Resource Description Framework. Met RDF beschrijf je entiteiten en hun relaties. Het idee van RDF is heel simpel en lijkt veel op hoe westerse talen zijn opgebouwd: subject – predicaat – object. Het subject is datgene dat je wilt beschrijven, je onderwerp dus. Het predicaat is een eigenschap van het onderwerp die echter tevens iets zegt over het object. Subject en object zijn entiteiten, het predicaat vormt de relatie tussen beide entiteiten. Samen vormen subject, predicaat en object een zogenaamde RDF-triple. Voorbeelden van triples zijn:
- Max (subject) houdt van (predicaat) computers (object).
- Tijn loopt naar school.
- Bram kent Lieke.

In RDF worden subject, predicaat en object geïdentificeerd door zogenaamde URI’s (Uniform Resource Identifiers). Een URI is hetzelfde voor een entiteit als een burgerservicenummer (sofinummer) of paspoortnummer is voor ons. De URI geeft simpelweg eenduidig aan over welke entiteit of relatie we het hebben. Vaak is een URI een URL (webadres) met een toevoeging:
https://www.frankwatching.com/verdere-dingen-in-de-url/onderwerp
URI´s spelen een belangrijke rol in de bottom-up benadering want ze vormen de toegang tot alle informatie over die entiteit. Via de URI van Max bijvoorbeeld kunnen we alle informatie over Max vinden. Je kunt dit goed vergelijken met de manier waarop een sofinummer informatie over een persoon ontsluit.
Tot nu toe hebben we het telkens over losse triples, maar meestal heeft een entiteit meerdere relaties: “Max houdt van computers” , “Max kent Bram”, “Max is student” etcetera. Hoe meer triples er zijn bij een entiteit, hoe meer informatie er over beschikbaar is.
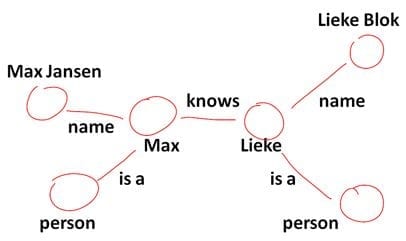
De triples beschrijven dus relaties tussen entiteiten, maar geven geen betekenis hieraan. Zelfs niet als je URI’s koppelt aan de onderdelen van de triple. Voor computers is het immers niet duidelijk dat “Max” een persoon is en “houden van” betekent dat Max iets of iemand (in ons voorbeeld computers) leuk vindt. Die betekenis ontstaat pas als je de triple koppelt aan een zogenaamde vocabulary. In vocabularies worden ontologieën beschreven. Een ontologie vertelt wat de RDF-triple betekent en geeft daarmee computers de mogelijkheid om te begrijpen waar die over gaat. Ontologieën worden beschreven in een taal die bekend staat als OWL (Web Ontology Language).
Een bekend voorbeeld van een ontologie is foaf. Foaf staat voor friend-of-a-friend en is gemaakt om mensen en hun relaties te beschrijven. Foaf stelt computers in staat om te begrijpen dat je het over een bepaalde persoon hebt. We kunnen een computer duidelijk maken dat Max’ volledige naam “Max Jansen” is door het juiste predicaat uit foaf te gebruiken.

Op ongeveer dezelfde manier kunnen we aangeven dat Max een persoon is en dat hij andere personen kent.
Kortom, triples beschrijven de relaties tussen entiteiten en met ontologieën geef je er betekenis aan. Het hele semantic web kun je nu construeren door triples te combineren met andere triples, die weer gecombineerd kunnen worden met weer andere triples.
De andere bouwstenen, GRDDL en SPARQL, dienen niet voor de constructie van het semantic web, maar voor het uitlezen ervan. SPARQL staat voor “SPARQL Protocol and RDF Query Language” en is bedoeld om hele verzamelingen van triples met één statement op te halen. Je kunt SPARQL zien als -voor lezers die daarmee bekend zijn- een SQL voor RDF-triples. Dat is handig want de informatie waarnaar je op zoek bent kun je op die manier gemakkelijk uit het hele web trekken.
Voordat je een zoekvraag maakt met SPARQL kun je je informatiescope nog verbreden door GRDDL te gebruiken. RDF is namelijk niet de enige manier om entiteiten te beschrijven. Entiteiten kunnen ook beschreven worden door bijvoorbeeld meta-tags of microformats. GRDDL betekent “Gleaning Resource Descriptions from Dialects of Languages” en schraapt als het ware alle verschillende annotatiemethodes bij elkaar en maakt er RDF van, die dan weer met behulp van SPARQL opgevraagd kan worden.
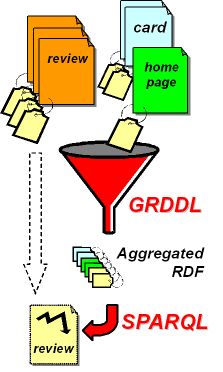
Wat je met SPARQL kunt doen is zeer krachtig, tenminste in de ideale situatie dat het hele web netjes met RDF geannoteerd is. Ben je bijvoorbeeld op zoek naar een vakantiehuisje in Frankrijk dat aan specifieke wensen voldoet, dan zorgt SPARQL ervoor dat je een lijst met exact die huisjes krijgt. Geen vervuiling dus met verkeerde zoekresultaten.
Een voorbeeld van een applicatie waarbij entiteiten met RDF zijn vastgelegd -en dus uitgevraagd kan worden met SPARQL- is DBpedia, de semantische variant van Wikipedia. DBpedia is een proefproject van de community die zich bezig houdt met de bottom-up benadering van het semantic web. Wikipedia is bewust gekozen omdat het zeer veel entiteiten bevat. Als je daar een semantische variant van maakt, zo was de gedachte, dan krijg je een goed beeld van hoe een heel semantic web er uit kan zien.
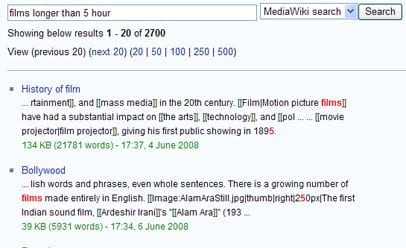
DBpedia is een academisch proefproject en heeft dus niet de gebruiksvriendelijke interface van Wikipedia. Je moet verstand hebben van SPARQL om er informatie uit te halen. Maar krachtig is het wel! Probeer maar eens bijvoorbeeld alle films die langer duren dan 5 uur uit Wikipedia te halen. Dat is vrijwel onmogelijk. DBpedia levert je binnen enkele seconden een lijstje dat niet foutloos is maar wel zinnige antwoorden bevat.
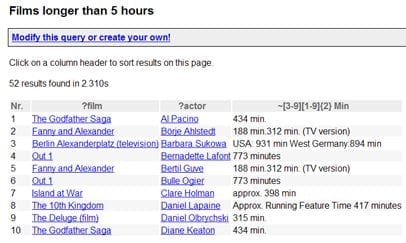
Je kunt in DBpedia in feite alle dingen vragen die je ook aan een database zou kunnen vragen. Voorbeelden hiervan zijn:
- Alle tennissers uit New York
- Wat Amsterdam en Rotterdam verbindt (antwoord: de New York State Route 5S)
- Liedjes die over Londen gaan
- Alle personen die 1.80m lang zijn
Als je de kracht van DBpedia ziet kun je je gemakkelijk de impact voorstellen als dit op het hele web zou werken. Helaas schuilen in die schaalvergroting ook de grootste moeilijkheden.
- URI’s zullen niet consequent gebruikt gaan worden. Een entiteit hoort uniek geïdentificeerd wordt door een URI. Maar als 2 mensen over George Bush schrijven kan het heel goed gebeuren dat de redacteur van het eerste artikel Bush koppelt aan zijn URL in Wikipedia, terwijl de tweede dat doet aan de URL georgebush.com. Het semantic web ziet beide Bush’s nu niet meer als dezelfde persoon, dus de informatie onder de verschillende URI’s is niet gelinkt. Dit leidt tot versnippering van informatie.
Daarnaast zullen URI’s foutief gebruikt gaan worden. In ons geval treedt dat op als informatie over George W. Bush per ongeluk wordt gelinkt wordt aan de URI van zijn vader George H.W. Bush. Je mist in dat geval informatie over George jr. onder zijn URI. Bovendien staat onder George sr. informatie over diens zoon. - Een tweede probleem betreft ontologieën. Hoe weet je zeker dat de betekenis die je voor ogen hebt bij een bepaalde eigenschap gedekt wordt door een bestaande ontologie? Misschien zijn er wel kleine -maar belangrijke- nuanceverschillen tussen jouw opvatting en de betekenis beschreven door de ontologie. Je kunt in dat geval zelf een nieuwe ontologie maken, dat leidt echter tot een wildgroei van ontologieën mochten beide ontologieën toch hetzelfde betekenen.
- Triples kunnen informatie bevatten die in feite onzin is. Spammers en oplichters kunnen bewust foute informatie aan entiteiten koppelen om hoger in zoekmachines te scoren of om mensen op het verkeerde been te zetten.
 Naast technische moeilijkheden zijn er menselijke. Een semantic web kan gemakkelijk leiden tot aantasting van anonimiteit en privacy. In mijn vorige artikel op Frankwatching schreef ik hierover. Mensen zullen hiermee moeten leren omgaan. Maar mensen zijn flexibel en creatief in het omgaan met nieuwe mogelijkheden. Hooguit vergt het aanpassingstijd. En eigenlijk bevinden we ons al op de weg van verminderde anonimiteit en privacy.
Naast technische moeilijkheden zijn er menselijke. Een semantic web kan gemakkelijk leiden tot aantasting van anonimiteit en privacy. In mijn vorige artikel op Frankwatching schreef ik hierover. Mensen zullen hiermee moeten leren omgaan. Maar mensen zijn flexibel en creatief in het omgaan met nieuwe mogelijkheden. Hooguit vergt het aanpassingstijd. En eigenlijk bevinden we ons al op de weg van verminderde anonimiteit en privacy.
De technische issues lijken me een groter struikelblok. Het slagen van de bottom-up benadering staat of valt met de gestructureerdheid van data. Het concept van de bottom-up benadering van Web 3.0 is in die zin totaal verschillend van Web 2.0. Structuren in Web 2.0 zijn juist erg informeel en ongestructureerd en laten de eindgebruiker veel vrijheid. De vrijheid van tagging is hiervan een voorbeeld. De bottom-up benadering van het semantic web vraagt juist structuur en controle.
Maar wellicht is de mens ook creatief genoeg om deze issues op te lossen. Tim Berners-Lee lijkt daar in ieder geval van overtuigd:
“I think… we’ve got all the pieces to be able to go ahead and do pretty much everything… [Y]ou should be able to implement a huge amount of the dream[..]. So, people are realizing it’s time to just go do it.”
Over de auteur



