 Employee Experience
Employee Experience NSA heeft de perfecte big data-strategie



In het boek ‘De big data revolutie’ van Viktor Mayer-Schönberger en Kenneth Cukier wordt in het eerste hoofdstuk uit de doeken gedaan hoe Google waarde haalt uit haar enorme vergaarbak van data. Als voorbeeld wordt de bekende Google Flu Trends-case aangehaald.
Google Flu Trends
De zoekmachine is in staat om de verspreiding van de wintergriep in de VS beter te voorspellen dan de Centers for Disease Control and Prevention (centra voor ziektebestrijding en -preventie). Niet alleen op landelijk niveau, maar per regio en zelfs per deelstaat. Simpelweg door het zoekgedrag van haar gebruikers te analyseren.
“De mensen van Google hadden erop gegokt dat de zoekers uit waren op het verkrijgen van informatie over griep – met behulp van zoektermen als ‘medicijn voor hoest en koorts’ –, maar dat bleek niet de crux te zijn. Daarom ontwierpen ze een systeem waarbij het er niet toe deed waar mensen naar zochten. Het systeem zocht alleen maar naar correlaties tussen de frequentie van bepaalde zoekopdrachten en de verspreiding van de griep in tijd en ruimte.
In totaal verwerkten ze maar liefst 450 miljoen verschillende wiskundige modellen voor het testen van de zoektermen en vergeleken ze de voorspellingen met de gegevens van de CDC’s over werkelijke griepgevallen in 2007 en 2008. En ze stuitten op een goudmijn: hun software vond een combinatie van vijfenveertig zoektermen die, indien ze samen werden ingevoerd in een wiskundig model, een sterke correlatie lieten zien tussen de voorspellingen en de officiële landelijke cijfers. Ze konden net als de CDC’s aangeven waar de griep zich had verspreid, maar anders dan de CDC’s konden ze dat bijna realtime in plaats van pas een paar weken later.”
De strategie van NSA
Deze week lekte uit dat de NSA een zelfde strategie als Google hanteert. Het zoveel mogelijk binnenslurpen van data en deze met elkaar in verband brengen. Door de data van onder andere Verizon, Google, Facebook en Apple met elkaar te combineren, krijgt NSA een steekproef van N=alles in handen. PRISM heet het initiatief. Een mooie naam, om aan te geven dat vanuit verschillende invalshoeken de verzamelde en gecombineerde data leidt tot nieuwe inzichten. Een ware goudmijn voor de Amerikaanse inlichtingendiensten.
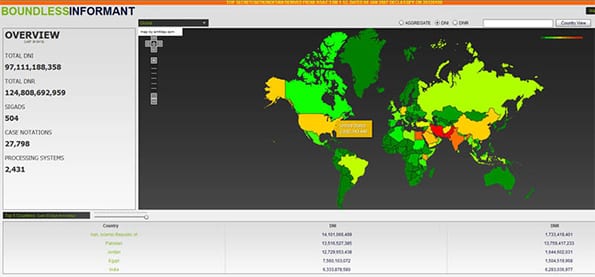
Creepy is het wel
Uiteraard is rondom dit initiatief veel commotie ontstaan. Big Brother is watching you! Gaat de Amerikaanse overheid niet veel te ver met dit initiatief? Schenden de Verenigde Staten hier niet de privacy van miljoenen burgers? Nu schreeuwen we moord en brand omdat de Amerikaanse overheid al deze data heeft vergaard middels geheime afspraken. Wij hebben geen controle of inzicht op het profiel dat van ons allen wordt aangemaakt. Ben ik een terrorist in de ogen van de Verenigde Staten? En indien deze geaggregeerde conclusie onterecht is, hoe kan ik deze veranderen? Of zit ik voor de rest van mijn leven aan deze stempel vast? Creepy is het dus wel.
De data ligt al op straat
Frappant is echter dat een groot deel van dezelfde data al op straat ligt. Iedereen kan profielen van iedereen maken door informatie van onder andere Facebook, Twitter en Pinterest met elkaar te combineren. Sterker nog, we vinden het niet meer dan normaal wanneer er een gepersonaliseerde advertentie in onze tijdlijn staat. En ook hier hebben we nauwelijks invloed op het digitale alterego dat de diverse algoritmes van ons maken. Hier vinden we het goed. We betalen met onze privacy om te kunnen kijken in het leven van anderen. En vinden het niet erg wanneer een ander naar ons gluurt.
In het vierde en laatste trendrapport ‘Uw Big-Data potentieel – The Art of the Possible‘ wordt de peilstok gestoken in de vraag hoe het big data-potentieel binnen organisaties en instanties nu wordt verwezenlijkt en hoe ver we daarmee zijn. Om big data-potentieel aan te boren, moet je de kunst verstaan het mogelijke te verkennen en het schijnbaar onmogelijke mogelijk te maken. Big data is je nieuwe collega en de missie is om radicale ideeen naar binnen te brengen en uit te voeren: science fiction gebaseerd op science facts. De enige beperking bij big data is het eigen voorstellingsvermogen.
Niets is meer onmogelijk
De kern van alle big data-initiatieven is om buiten de eigen datagrenzen te kijken, en op zoek te gaan naar interessante combinaties van interne en externe, gestructureerde en ongestructureerde data. De executie van PRISM laat eens te meer het potentieel van een goede big data-strategie zien. Het is de kunst om het onmogelijke mogelijk te maken. En wat PRISM laat zien is dat niets meer onmogelijk is.
Over de auteur



