 Employee Experience
Employee Experience Waarom geeft internet nog geen antwoord op de echt belangrijke vragen?



Er wordt vaak gezegd dat alle antwoorden op bijna elke vraag op internet te vinden zijn. Hoe komt het dan dat we nog steeds geen antwoorden kunnen vinden op vragen die bijna elk bedrijf of organisatie heeft? En hoe kunnen we ervoor zorgen dat we die antwoorden wel vinden?
Echt belangrijke vragen
Vragen waar bedrijven antwoord op willen, zijn bijvoorbeeld:
- Wie zijn de belangrijkste personen of beïnvloeders in mijn industriesector?
- Wie zijn mijn fans, of mijn critici?
- Wat schrijft men in de verschillende landen over mijn organisatie, product, mijn mensen?
- Wat zijn de belangrijke trends in mijn sector?
- Welke evenementen domineren mijn bedrijfstak?
- Waar zitten mijn fans, critici en beïnvloeders?
- Wanneer en waar worden er discussies gevoerd over mijn merk, organisatie of product?
Computers die onze gedachten lezen en ordenen als oplossing
Wat we echt willen weten, is het antwoord op de vragen: Wie, Wat, Waar, Wanneer. Dus waar mensen op een bepaalde plaats in de wereld op een bepaald moment aan denken. Wij kunnen dat onmogelijk weten, omdat het niet mogelijk is om alle gedachten die worden vastgelegd in blogs, tweets of posts op een dag aan te horen of te lezen, daarvoor zitten er te weinig uren in een dag en daarvoor is ons brein te licht.
Wat we wel zouden kunnen proberen, is om een steekproef te nemen uit al deze gedachten, en van daaruit een soort van samenvatting te creëren. Om dit te doen moeten we dus computers inschakelen die alle gedachten verzamelen en deze gedachten onderbrengen in categorieën. Hoe dat werkt? Ik leg het je hieronder uit.
Stap 1. Categoriseren van menselijke gevoelens en emoties
Je kunt je voorstellen dat we emoties gaan vatten in bepaalde categorieën. Je gevoelens in hokjes plaatsen als het ware. Dit is gelukkig al gedaan voor ons door linguïsten, wetenschappers die de taal bestuderen.
Voor wat betreft emoties, gevoelens, zijn er 6 hoofdcategorieën bedacht: woede, spanning, vermoeidheid, verwarring, depressie en kracht. Meestal worden ze in het Engels aangegeven, omdat de wetenschap zich op dit moment met name concentreert op de Engelse taal. De categorieën heten dan: Anger, Tension, Fatigue, Confusion, Depression and Vigor.
In de Engelse taal kun je vervolgens emotiewoorden onderbrengen in elk van deze categorieën. Denk daarbij aan woorden zoals bijvoorbeeld happy, angry, shy, delightfull, embarresed, powerfull. Je herkent emotiewoorden aan het feit dat het woorden zijn waar je woordcombinaties voor kunt zetten als “I am feeling …”, “I feel …”, “We are feeling …”, “We feel …”, “Makes me feel …” etc.
Daarnaast heb je nog zogenaamde indicators. Indicators zijn woorden die de sterkte van een emotie aangeven, zoals “as a”, “really”, “a little bit” etc.
Stap 2. Begrijpend lezen in vreemde talen automatiseren
De grote uitdaging bij het ontwikkelen van een computerprogramma dat bovenstaande kan faciliteren, ligt in het feit dat je een systeem moet ontwerpen dat een stuk tekst kan analyseren op basis van al deze woorden, en die vervolgens een uitspraak doet over de ‘emotional state’ van de schrijver van dat stuk tekst.
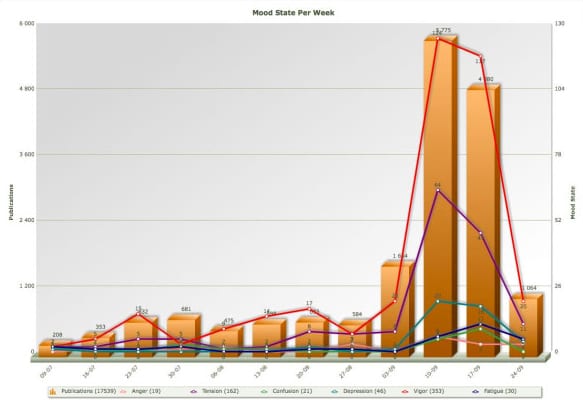
De release van een nieuw model iPhone leidt tot veel enthousiasme en spanning
Helaas zijn wij mensen heel goed in het omzeilen van deze theorie, we noemen dat dan cynisme of sarcasme. Neem bijvoorbeeld de zin: “I feel like I have been ran over by a truck”. Dat is een uitdrukking die je niet kunt vangen met vaste regels.
Je moet dus als ontwikkelaar van een systeem voor ‘emotion finding’ eigenlijk eerst een hele range van alle voorkomende uitzonderingen vastleggen om een bepaalde mate van accuratesse te verkrijgen. Hier ligt dan ook direct de uitdaging. Dit gaat eigenlijk nooit voor 100% lukken. Net als je denkt: “Ik ben klaar”, dan is er wel weer een nieuwe uitdrukking gevonden door iemand die zeer snel door mensen wordt begrepen en overgenomen.
Zeker als je teksten vertaalt vanuit een vreemde taal naar het Engels, dan weet je ook zeker dat bepaalde uitdrukkingen in een andere taal helemaal niet voorkomen. “De verkoper heeft mij knollen voor citroenen verkocht”, is goed te vertalen, maar wordt niet meer begrepen door iemand die deze vertaling leest! Dus wat te doen?
Stap 3. Gebruik de kracht van big data en statistiek
Omdat wetenschappers weten dat bovenstaand probleem niet makkelijk is op te lossen, grijpt men terug naar de wetenschap van de statistiek. Om een uitspraak te doen over een grote groep, oftewel ‘populatie’, moet je een steekproef nemen. Je bent dan wel niet meer 100% accuraat, maar doordat je voor, zeg, 90% accuraat wilt zijn, kun je toe met een fractie van alle uitingen.
Dit is precies wat er nu gaande is binnen het vakgebied van sentimentanalyse of opinion mining. Je analyseert op een bepaald moment een hele grote groep documenten die komen van een bepaalde plaats, geuit door een bepaalde groep mensen, en het zal dan blijken dat je uit maar 8% van deze documenten een ‘emotional state’ kan halen. Maar dit is ruim voldoende om een uitspraak te doen over de totale groep.
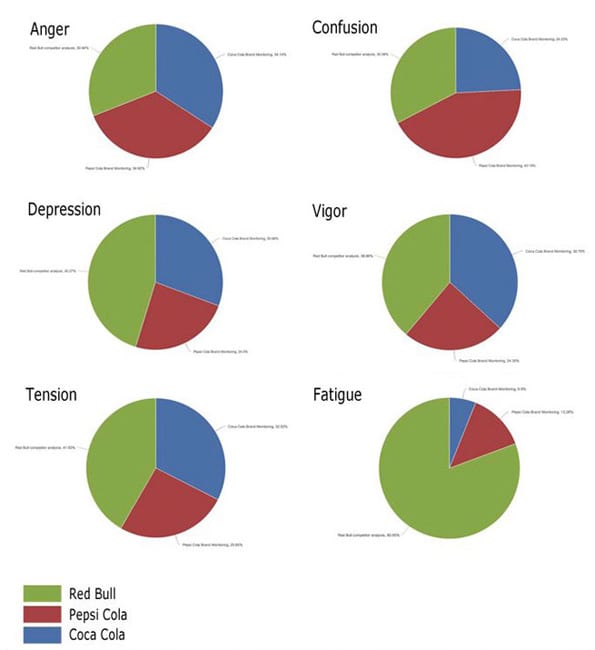
Het merk ‘Red Bull’ wordt omgeven door emoties van vermoeidheid en depressie
Een geweldig voorbeeld hoe dit werkt is de website We Feel Fine, gemaakt door Jonathan Harris en Sep Kanvar.
Stap 4. Duiden van de gevonden informatie
Je bent er nog niet als je alleen maar weet hoe een bepaalde groep mensen zich voelt op een bepaald moment. Je wilt ook weten waarom zich zo voelen, je wilt ook weten waar ze het over hebben, en als ze het dan over iets hebben, hoe denken ze dan over dat ‘iets’. Zijn ze positief of negatief over dat ‘iets’?
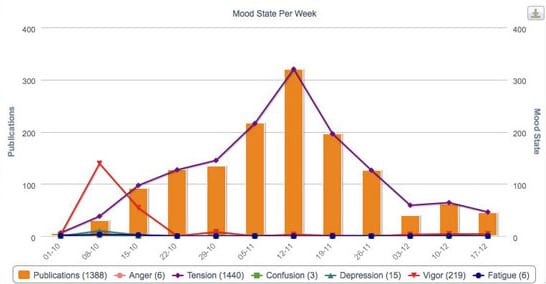
Spanning over de naderende ‘X-mas is coming’ commercial van Coca Cola
Wil je echt een praktisch systeem bouwen, dan moet je niet alleen bepalen wat de emotionele toestand is van de schrijver (als die al iets loslaat daarover) maar je wil ook weten waar hij over schrijft en of hij positief of negatief over iets schrijft. De methode om dit te achterhalen blijft hetzelfde, eerst categorieën maken, dan woordenlijsten onder deze categorieën hangen, dan lijsten aanleggen met ‘indicators’ om te bepalen wat de zwaarte is van de negativiteit of positiviteit.
Waar zijn we nu?
De wetenschap rondom het analyseren van teksten heeft de laatste jaren een grote vlucht genomen. Iedereen kan op zijn vingers natellen dat het geweldig zou zijn wanneer niet wijzelf, maar een computer de taak zouden geven om duizenden documenten per dag te lezen, en ons dan – liefst op 1 A4tje – zou vertellen dat bijvoorbeeld 65% van de mensen in Nederland die deze week schoenen willen gaan kopen, voor 55% warme gevoelens hebben bij het merk NIKE, vinden dat schoenen van NIKE voor 80% lekker zitten, voor 90% cool eruit zien en 35% een goede prijs/kwaliteitsverhouding hebben.
Helaas zijn er op dit moment nog geen systemen die precies dat kunnen. Wel worden er pogingen ondernomen. We kennen een bedrijf als Thomson Reuters, dat via een dienst genaamd OpenCalais ‘feiten’ haalt uit documenten. Zaken als: “In dit document vinden we een bedrijfsnaam: NIKE, een persoonsnaam: Michael Jordan, een Industry Term: Cool”, etc.
Welke patronen hebben een voorspellende waarde?
Door feiten te koppelen aan andere duidingen van het document zoals sentiment en mood states kunnen patronen zichtbaar gemaakt worden. Het vergt nog wel meer onderzoek om te ontdekken welke patronen voorspellende waarde hebben. In elk geval is wel duidelijk dat het niet een enkele factor is, maar eerder een samenspel van verschillende variabelen die tezamen kunnen vertellen hoe mensen op een bepaald moment over ‘iets’ denken en voelen en wat dat dan voor implicaties heeft.
Veel organisaties en wetenschappelijke instituten, zoals SentimentMetrics, SocialMood, IBM en ook mijn bedrijven zoeken naar de magische formule. Wanneer dit inzicht eenmaal is verworven kan het gekapitaliseerd worden. Daarbij zijn nog heel wat hobbels te nemen. Kennis is macht, geldt ook in de moderne wereld. En data scientists die hun analytische vaardigheden kunnen combineren met marktinzicht om de informatie te vertalen naar commerciële adviezen hebben de toekomst.
Foto intro met dank aan Fotolia
Over de auteur



