Zo beïnvloed je het crawlen en indexeren van je website


De vele technische mogelijkheden om het crawlen en indexeren van je website te beïnvloeden kunnen verwarrend zijn, voornamelijk als technieken samen gebruikt worden. Ik behandel in dit artikel zes technische SEO-aspecten die gebruikt worden om zoekmachine-indexatie te beïnvloeden.
De zes technische SEO-aspecten zijn:
- Robots.txt
- Meta robots
- Canonical-tag
- Canonical-tag combineren met noindex
- Rel=”next”/”prev” tag
- Rel=”next”/”prev”-tag combineren met canonical-tag
- Hreflang-tag
- Hreflang-tag combineren met canonical tag
- Hreflang-tag combineren met rel=”next”/”prev”
- Google Search Console-parameters
De eerste vijf aspecten zijn ook in een stroomschema gezet dat je onderaan dit artikel vindt. Dit stroomschema kun je per pagina volgen om de pagina SEO-technisch goed te zetten.
Vooraf wil ik een kleine waarschuwing meegeven. Het aanpassen van deze technische SEO-aspecten kan grote gevolgen hebben. Het is aan te raden om hier voorzichtig mee om te gaan.
Robots.txt
Robots.txt is een klein tekstbestand dat instructies bevat voor bots. Via dit bestand is het mogelijk om op domeinniveau bots aan te sturen om bepaalde domeinen, mappen, pagina’s, bestanden of specifieke URL’s niet te crawlen. Vaak wordt de zoekfunctie van een website middels robots.txt uitgesloten van crawlen. Dit wordt gedaan omdat deze URL’s niet gewenst zijn in de zoekresultaten van een zoekmachine. De zoekresultatenpagina kun je namelijk (vaak) niet optimaliseren voor elke zoekopdracht.
Let er op dat de instructies in de robots.txt richtlijnen zijn. Het zijn voor bots geen verplichtingen. De robots.txt staat altijd direct achter de domeinextensie in de URL. Bijvoorbeeld https://www.domein.nl/robots.txt. In het geval van een WordPress-website kan de robots.txt er zo uitzien:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpSitemap: https://www.domein.nl/sitemap_index.xml
Robots.txt biedt de gebruiker de mogelijkheid om voor alle bots instructies te geven of juist voor een bepaalde bot: bijvoorbeeld alleen Googlebot of Bingbot. Dit wordt aangegeven door de “user-agent” en dat ziet er zo uit:p
- User-agent: Googlebot → Dag Googlebot, welkom op mijn website. De volgende instructies zijn voor jou.
- User-agent: Bing → Dag Bingbot, welkom op mijn website. De volgende instructies zijn voor jou.
- User-agent: * → Dag alle bots, welkom op mijn website. De volgende instructies zijn voor jullie.
De laatste user-agent met een ‘*’ geeft instructies voor alle bots.
Een enkele pagina uitsluiten
Als je een pagina niet geïndexeerd wil hebben, dan kun je deze uitsluiten middels de ‘disallow’-instructie. Dit doe je als volgt:
User-agent: Googlebot
Disallow: /ditisdepaginadieiknietgecrawldwilhebben.html
Dag Googlebot, welkom op mijn website. Pagina /ditisdepaginadieiknietgecrawldwilhebben.html mag je niet bezoeken.
Een map uitsluiten
Wil je een gehele map uitsluiten dan gebruik je:
User-agent: Googlebot
Disallow: /ditisdemapdieiknietgecrawldwilhebben/
Dag Googlebot, welkom op mijn website. Map /ditisdemapdieiknietgecrawldwilhebben/ mag je niet bezoeken.
Bovenstaande tekst betekent dat onderliggende pagina’s ook niet bezocht mogen worden. Dus:
Dag Googlebot, welkom op mijn website. Map /ditisdemapdieiknietgecrawldwilhebben/paginahierondermagjeooknietbezoeken.html
Toegang toestaan
Daarnaast is er de ‘allow’-instructie. Hiermee geef je aan wanneer je een pagina wel geïndexeerd wil hebben. Standaard crawlt een bot alles, dus alleen pagina’s toevoegen met de instructie allow is niet nodig. Waarom bestaat dan de allow-instructie? Het kan zijn dat je een bepaalde map niet gecrawld wil hebben door een bot, maar dat iets binnen die map wel weer mag worden gecrawld. Je krijgt dan:
User-agent: Googlebot
Disallow: /ditisdemapdieiknietgecrawldwilhebben/
Allow: /ditisdemapdieiknietgecrawldwilhebben/maardezepaginawel.html
Dag Googlebot, welkom op mijn website. Map /ditisdemapdieiknietgecrawldwilhebben/ mag je niet bezoeken maar pagina “/maardezepaginawel.html” binnen die map wel.
URL’s blokkeren op basis van tekens
Naast het blokkeren van gehele mappen of pagina’s is het ook mogelijk om URL’s te blokkeren die bepaalde tekens bevatten. Dit wordt met het karakter ‘*’ gedaan. Als ik het volgende in de robots.txt toevoeg, dan worden alle URL’s geblokkeerd met een vraagteken er in:
User-agent: Googlebot
Disallow: /*?
Dag Googlebot, welkom op mijn website. Alle URL’s die een vraagteken bevatten mag je niet bezoeken.
Bestanden blokkeren
Tot slot kun je het dollarteken ($) gebruiken om URL’s met hetzelfde einde uit te sluiten. Als je een map hebt met verschillende soorten bestanden, waarvan je alleen de pdf-bestanden wilt blokkeren dan voeg je dit toe:
User-agent: Googlebot
Disallow: /*.pdf$
Dag Googlebot, welkom op mijn website. Alle URL’s die eindigen op .pdf mag je niet bezoeken.
Sitemap in robots.txt
De locatie van de sitemap kan ook toegevoegd worden in de Robots.txt. Dit kan helpen om bepaalde pagina’s binnen de website beter geïndexeerd te krijgen. De sitemap is een overzicht van alle pagina’s van een website.
De robots.txt wil je eigenlijk altijd toevoegen. Met name omdat je daarin kunt verwijzen naar de sitemap wat kan bijdragen aan het beter laten indexeren van pagina’s. Het biedt daarnaast de mogelijkheid om pagina’s of mappen te blokkeren voor zoekmachines. Heb je geen robots.txt toegevoegd, dan kunnen bots alles bezoeken van je website.
Het instellen van de robots.txt is geheel afhankelijk van de website. Sommige websites geven bots alle ruimte, andere websites beperken het bezoek. Het is altijd goed om na te gaan of je alle pagina’s van je website bezocht wilt hebben door bots. Het is daarbij verstandig om te onthouden dat het blokkeren van een pagina middels robots.txt niet altijd betekent dat de pagina niet geïndexeerd wordt. Als er veel externe links naar die pagina bestaan, dan zal de pagina wel geïndexeerd kunnen worden maar dan weet een zoekmachine niet wat er op die pagina staat.
Meta robots
Meta robots zijn instructies die in de broncode van je webpagina staan. Met deze codes is het mogelijk om per pagina van je website instructies te geven aan bots. De codes plaats je in de <head> van je pagina.
Instructies voor de meeste bots:
<meta name="robots" content="noindex">
Hallo bot, welkom op deze pagina. Je mag deze pagina niet indexeren.
En voor een specifieke bot:
<meta name="Googlebot" content="noindex">
Hallo Googlebot, welkom op deze pagina. Je mag deze pagina niet indexeren en dus niet vertonen in de zoekresultaten.
Zoals in de code hierboven aangegeven staat, zegt de eerste meta robot (noindex) tegen bots dat de pagina niet geïndexeerd mag worden. De tweede code geeft specifiek instructies aan Googlebot. De noindex meta robot is ook te gebruiken om duplicate content te vermijden. Je kunt er voor kiezen om een pagina niet te laten indexeren ALS deze te veel lijkt op een andere pagina.
Er zijn meer meta robots die je kunt gebruiken op een webpagina. Ik som veelgebruikte meta robots hieronder op:
- Nofollow
Code: <meta name=”Googlebot” content=”nofollow”>
Hallo Googlebot, welkom op deze pagina. Je mag de links die op deze pagina staan niet volgen. - Nosnippet
Code: <meta name=”Googlebot” content=”nosnippet”>
Hallo Googlebot, welkom op deze pagina. De informatie op deze pagina mag je niet gebruiken in de snippet in de zoekresultaten. - Noarchive
Code: <meta name=”Googlebot” content=”noarchive”>
Hallo Googlebot, welkom op deze pagina. In de zoekresultaten mag je geen ‘in cache’-optie tonen bij deze link. - Unavailable_after[datum]
Code: <meta name=”Googlebot” content=”unavailable_after:[vul datum in volgens RFC 850 indeling]”>
Hallo Googlebot, welkom op deze pagina. Na deze datum mag deze pagina niet meer geïndexeerd worden. - Noimageindex
Dit weerhoudt een bot ervan om afbeeldingen op een pagina te indexeren.
Code: <meta name=”Googlebot” content=”noimageindex”>
Hallo Googlebot, welkom op deze pagina. De afbeeldingen op deze pagina mogen niet geïndexeerd worden. - None
Dit is een verkorte versie van noindex en nofollow samen.
Code: <meta name=”Googlebot” content=”none”>
Hallo Googlebot, welkom op deze pagina. Deze pagina mag niet worden geïndexeerd en de links op deze pagina mogen niet worden gevolgd.
Deze instructies kunnen worden gebruikt binnen de broncode van een pagina. De ‘nofollow’-instructie kan ook gebruikt worden voor links naar andere pagina’s binnen jouw website of andere websites. Je geeft dan de nofollow-instructie mee aan een enkele link.
Als je er zeker van wil zijn dat een pagina niet geïndexeerd wordt door een zoekmachine, dan is het verstandig om deze pagina zowel in de robots.txt uit te sluiten als een no index meta robot op de pagina te plaatsen.
Canonical tag
De canonical tag is een manier om duplicate content te vermijden en om aan te geven welke pagina de belangrijkste pagina is. Dit is het beste uit te leggen door middel van een voorbeeld. Stel, je hebt een webshop in schoenen en je bekijkt alle schoenen voor mannen: https://www.domein.nl/mannenschoenen. Je komt op de webpagina terecht met alle schoenen voor mannen. Vaak kun je op zo’n pagina filteren op kleur, maat, merk en nog meer attributen. Tevens is het mogelijk om de producten te rangschikken op prijs en naam. Bijvoorbeeld: https://www.domein.nl/mannenschoenen?ord=price. De standaardpagina heeft een H1-tag ‘mannenschoenen’, eventueel meerdere H2-tags en een begeleidende tekst (content).
Als een bezoeker een andere volgorde in de producten wil, dan verandert de URL en heb je feitelijk een tweede pagina. Op die tweede pagina staan dezelfde H1- en H2-tags en content. Je hebt als het ware de standaardpagina met alle mannenschoenen en dezelfde pagina, met producten in andere volgorde, met dezelfde inhoud: duplicate content. Door een canonical tag kun je de bot laten weten wat de originele pagina is. Je zegt:
Hallo Googlebot, pagina https://www.domein.nl/mannenschoenen/ord=price bevat dezelfde inhoud als https://www.domein.nl/mannenschoenen maar https://www.domein.nl/mannenschoenen is de pagina die je moet indexeren.
Ditzelfde geldt voor wanneer een product binnen meerdere categorieën valt. Dit is bijvoorbeeld in het volgende geval zo:
https://www.domein.nl/mannenschoenX (origineel)
https://www.domein.nl/mannenschoenen/mannenschoenX
https://www.domein.nl/mannenschoenen/merkX/mannenschoenX
In bovenstaand voorbeeld bestaan er drie pagina’s voor het product mannenschoenX. In dit geval is het verstandig om een van deze pagina’s als origineel te bestempelen (de pagina met de meeste waarde, dus de belangrijkste pagina) en aan de andere twee pagina’s een canonical tag naar deze originele pagina toe te kennen:
https://www.domein.nl/mannenschoenX (origineel)
https://www.domein.nl/mannenschoenen/mannenschoenX
<link rel="canonical" href="https://www.domein.nl/mannenschoenX/">
https://www.domein.nl/mannenschoenen/merkX/mannenschoenX
<link rel="canonical" href="https://www.domein.nl/mannenschoenX/">
Als je dit niet doet, dan weet de zoekmachine niet wat voor jouw website de beste pagina is voor deze inhoud en kiest dan zelf welke pagina hij indexeert. Om dat te vermijden wijs je zelf een pagina aan als origineel die moet worden geïndexeerd. Zo houd je meer controle over de indexatie. Je plaatst de canonical tag in de head van de pagina.
Canonical tag combineren met noindex
De canonical blijkt dus een krachtig middel om pagina’s met duplicate content uit te sluiten van indexatie. Eerder besproken middelen zijn de noindex- en de nofollow-tags. Het is niet verstandig om zowel een canonical tag als no index meta robot te gebruiken. In theorie geef je daarmee twee signalen af. De canonical-tag geeft aan dat de pagina’s (bijna) identiek zijn. Terwijl de noindex-tag aangeeft dat je de pagina’s verre van identiek zijn (Schwarts, 2014). Gebruik dus óf de no index-tag, óf de canonical-tag.
Rel=”next”/”prev” tag
Wanneer een categorie veel producten heeft dan kan die categorie opgesplitst worden in meerdere pagina’s.
De relatie tussen deze gepagineerde inhoud kun je aangeven in de broncode van een webpagina, namelijk in de <head> (Valk, 2018). De eerste pagina is (bijna) altijd de categoriepagina. Bijvoorbeeld: https://www.domein.nl/mannenschoenen/.
Als ik 50 paar schoenen in een categorie hebt, met 12 schoenen per pagina, dan heb ik pagina 1 tot en met 5. Dat kan er als volgt uitzien:
https://www.domein.nl/mannenschoenen/
https://www.domein.nl/mannenschoenen/?page=2
https://www.domein.nl/mannenschoenen/?page=3
https://www.domein.nl/mannenschoenen/?page=4
https://www.domein.nl/mannenschoenen/?page=5
Als ik zoals hierboven meerdere pagina’s heb die achter elkaar horen, dan kan ik in de broncode van /mannenschoenen verwijzen naar de volgende pagina:
https://www.domein.nl/mannenschoenen/?page=2
Dit doe ik door op de pagina https://www.domein.nl/mannenschoenen/ de volgende code te gebruiken:
<link rel="next" href="https://www.domein.nl/?page=2">
Wanneer ik op pagina 2 zit dan wil ik verwijzen naar de vorige en volgende pagina. In dat geval voeg ik twee stukken code toe:
<link rel="prev" href="https://www.domein.nl/mannenschoenen"> <link rel="next" href="https://www.domein.nl/?page=3">
Let hierbij op dat ik vanaf pagina twee terug verwijs naar de categoriepagina (/mannenschoenen/) pagina en niet naar /mannenschoenen/?page=1. Wanneer ik dat laatste zou doen dan heb ik, zonder het gebruik van een canonical, dubbele content voor de eerste pagina: namelijk /mannenschoenen en /mannenschoenen/?page=1.
Voor pagina 3 verwijs ik naar /?page=2 en /?page=4 enzovoorts.
De laatste pagina (in dit voorbeeld pagina 5) heeft alleen een verwijzing naar de vorige pagina:
<link rel="prev" href="https://www.domein.nl/mannenschoenen/?page=4">
Het is belangrijk om volledig te zijn in het implementeren van deze tag. Vergeet je op een van de pagina’s (een stuk van) de code dan ziet de bot de relatie tussen de pagina’s niet of minder goed en gaat deze zelf de relatie te zoeken. Hierdoor kunnen er indexatieproblemen ontstaan.
Rel=”next”/”prev” combineren met canonical
Voor categoriepagina’s met paginering wil je geen canonical van de ene pagina naar een andere pagina. De rel= “prev”/”next”-code geeft de relatie tussen pagina’s weer wat problemen met duplicate content voorkomt. Sommige CMS’en plaatsen automatisch op elke pagina een canonical tag. Wat dan vaak fout gaat is dat pagina’s 2 en verder een canonical tag hebben staan naar de eerste pagina.
Als je de canonical tag wil gebruiken in combinatie met de rel=”next”/”prev”-tag, dan moet de canonical van de pagina naar zichzelf verwijzen. Dus de pagina https://www.domein.nl/mannenschoenen/?page=2 heeft een canonical naar zichzelf: Rel=”canonical” href=”https://www.domein.nl/mannenschoenen/?page=2″
Als de canonical van pagina 2 verwijst naar pagina 1, kunnen producten en inhoud van pagina 2 niet geïndexeerd worden. Een naar zichzelf verwijzende canonical wordt ook wel een self referencing canonical genoemd.
Hreflang-tag
De hreflang-tag gebruik je als een website meerdere taalinstellingen heeft. Het is met deze tag mogelijk om bots te verwijzen naar versies van de website in een andere taal. Als ik naast de Nederlandse versie bijvoorbeeld ook een https://www.domein.com heb dan kan ik in de broncode verwijzen naar deze versie. Een zoekmachine herkent de hreflang-tag en schotelt de bezoeker dan de juiste versie van de website voor op basis van de locatie en taalinstellingen van de bezoeker (Valk, 2018).
Dit doe je door middel van de hreflang-tag en die ziet er zo uit: rel=”alternate” hreflang=”x”. De code plaats je in de <head> van de pagina.
Bij het gebruik van de hreflang-tag moet je het volgende in acht nemen. De Nederlandse website moet verwijzen naar de Engelse en andersom. Het is dus niet voldoende om alleen van de Nederlandse website naar de Engelse versie te verwijzen. Daarnaast dien je bij het gebruik van deze tag ook een self referencing-deel toe te voegen. Een klein voorbeeld:
Broncode Nederlandse versie
https://www.domein.nl
<link href="https://www.domein.nl/" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/" hreflang="en" rel="alternate" />
Broncode Engelse versie
https://www.domein.com
<link href="https://www.domein.nl/" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/" hreflang="en" rel="alternate" />
Met de hreflang-tag is het ook mogelijk om je website in te richten voor taalregio’s. Bijvoorbeeld België heeft een Franstalig deel en een Nederlandstalig deel. Ik kan mijn website dus inrichten voor Franstalig België met:
<link href=”https://www.domein.be/fr” hreflang=”fr-be” rel=”alternate” />
en Nederlandstalig België met:
<link href=”https://www.domein.be/” hreflang=”nl-be” rel=”alternate” />
Houd er rekening mee dat dit voor elke pagina op de website moet worden ingesteld. Het is dus niet voldoende om alleen op de homepage een hreflang-tag te plaatsen. Dus een Nederlandse categoriepagina verwijst naar de Nederlandse en Engelse categoriepagina, en andersom. De Nederlandse productpagina verwijst naar de Nederlandse en de Engelse productpagina, en andersom.
Hreflang combineren met canonical-tag
Als je de hreflang-tag wil combineren met een canonical-tag, dan moet je binnen dezelfde taal verwijzen met de canonical-tag (Moz, 2018). Als ik vanaf mijn Nederlandse website met de hreflang-tag verwijs naar de Engelse versie, dan wil ik de canonical naar de Nederlandse versie hebben staan. Dit komt door de verschillende signalen die de twee oplossingen zenden. Zoals besproken geeft de canonical-tag een voorkeur aan om de belangrijkste pagina wel te laten indexeren en de minst belangrijke pagina’s niet. De hreflang-tag geeft aan welke andere versies van de website je ook in de zoekresultaten wil hebben. Dit zijn dus tegenstrijdige signalen.
Om het compleet te maken volgen hieronder de voorbeelden van hreflang-tag met canonical-tag.
Broncode Nederlandse versie
https://www.domein.nl
<link href="https://www.domein.nl/" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/" hreflang="en" rel="alternate" /> <link rel="canonical" href="https://www.domein.nl/">
Broncode Engelse versie
https://www.domein.com
<link href="https://www.domein.nl/" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/" hreflang="en" rel="alternate" /> <link rel="canonical" href="https://www.domein.com/">
Hreflang combineren met rel=”next”/”prev”
Combineer je de hreflang-tag met de rel=”next”/”prev”-tag dan moet je logischerwijs rekening houden met de volgende dingen. Zorg er voor dat je de rel=”next”/”prev”-tag binnen een taalversie van de website gelijk houdt. Je moet dus niet in de Nederlandse versie van de website de rel=”next”/”prev”-tag gebruiken met een .com-webadres. Daarnaast moet een Nederlandse pagina 2 door middel van de hreflang-tag verwijzen naar de Nederlandse pagina 2 en naar de Engelse pagina 2.
Omdat voorbeelden vaak handiger werken, heb ik hieronder stukken broncode geplaatst.
Broncode Nederlandse versie
https://www.domein.nl/mannenschoenen
<link href="https://www.domein.nl/mannenschoenen" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/mensshoes" hreflang="en" rel="alternate" /> <link rel="canonical" href="https://www.domein.nl/"> <link rel="next" href="https://www.domein.nl/mannenschoenen/?page=2">
Broncode Nederlandse versie
https://www.domein.nl/mannenschoenen/?page=2
<link href="https://www.domein.nl/mannenschoenen/?page=2" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/mensshoes/?page=2" hreflang="en" rel="alternate" /> <link rel="canonical" href="https://www.domein.nl//mannenschoenen/?page=2"> <link rel="next" href="https://www.domein.nl/mannenschoenen/?page=3"> <link rel="prev" href="https://www.domein.nl/mannenschoenen">
Broncode Engelse versie
https://www.domein.com/mensshoes
<link href="https://www.domein.nl/mannenschoenen" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/mensshoes" hreflang="en" rel="alternate" /> <link rel="canonical" href="https://www.domein.com/mensshoes"> <link rel="next" href="https://www.domein.com/mensshoes/?page=2">
Broncode Engelse versie
https://www.domein.com/mensshoes/?page=2
<link href="https://www.domein.nl/mannenschoenen/?page=2" hreflang="nl" rel="alternate" /> <link href="https://www.domein.com/mensshoes/?page=2" hreflang="en" rel="alternate" /> <link rel="canonical" href="https://www.domein.nl//mannenschoenen/?page=2"> <link rel="next" href="https://www.domein.com/mensshoes/?page=3"> <link rel="prev" href="https://www.domein.com/mensshoes">
Google Search Console URL-parameters
Met de Google Search Console parameters is het mogelijk om bovenstaande punten aan te geven bij Google (Google, 2018). Het kan zijn dat één of meerdere van deze technische aspecten niet aanpasbaar zijn in jouw CMS. In dat geval biedt Google Search Console URL-parameters een uitkomst. Als je inlogt bij Google Search Console dan kun je onder het tabje ‘crawlen’ de optie URL-parameters vinden.
Binnen Google Search Console URL-parameters kun je zelf parameters toevoegen die bezoekers kunnen gebruiken om content te ordenen of te filteren.
Na het toevoegen van een parameter kun je kiezen uit twee opties:
- De parameter heeft geen invloed op de pagina-content
- De pagina-content wordt gewijzigd, opnieuw ingedeeld of beperkt
Een parameter die geen invloed heeft op content is bijvoorbeeld sessie ID. Als je wel een parameter hebt die van invloed is op de content, bijvoorbeeld een sorteeroptie of een filter, dan kun je in Google Search Console aangeven wat de invloed is van deze parameter op de content. In onderstaande afbeelding is te zien dat de content beïnvloed kan worden door sorteren, beperken, specificeren, vertalen en pagineren.
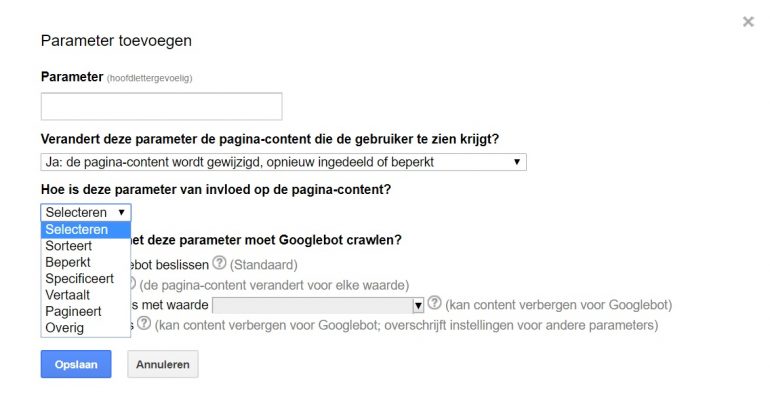
Vervolgens kun je aangeven wat Google met de URL’s die deze parameter bevatten, moet doen:
- Googlebot laten besluiten: als je niet zeker weet wat de parameter doet of wanneer het gedrag verschillend is op diverse delen van de website.
- Elke URL: op deze manier wordt elke wijziging van een parameter gezien als een aparte URL. Gebruik deze optie wanneer je zeker weet dat de content verandert bij het veranderen van de parameter.
- Alleen URL’s met opgegeven waarde: met deze optie kun je de waarde van een parameter opgeven die gecrawld moet worden. Als er een parameter op de website staat die producten sorteert op prijs, dan kun je aangeven dat alleen de URL’s die producten sorteren op prijs van hoog naar laag gecrawld mogen worden. URL’s die een prijs sorteeroptie van laag naar hoog bevatten worden dan niet gecrawld.
- Geen URL’s: deze optie biedt de mogelijkheid om URL’s met een parameter geheel uit te sluiten. Dit kan van pas komen als je in een URL meerdere parameters achter elkaar hebt.
Google Search Console URL-parameters bevat opties die ook door eerder genoemde middelen zijn te verhelpen. Kijken we bijvoorbeeld naar parameters die vertalen of pagineren dan zijn dat respectievelijk de eerder genoemde hreflang-tag en rel=”next”/”prev”-tag.
Als het implementeren van een bepaalde tag niet lukt, dan kun je via deze tool hetzelfde bereiken. Het is echter zo dat deze regels alleen voor de Google-zoekmachine gelden, terwijl de tag-implementaties voor (bijna) alle zoekmachines gelden.
Stappenplan
Het is een lang stuk geworden over de technische kant van SEO. Om bovenstaande informatie kort samen te vatten heb ik een stappenplan gemaakt dat hieronder te zien is. Dit stappenplan kun je prima per pagina volgen om erachter te komen welke tags je precies moet implementeren. In de inleiding heb ik al gezegd dat je voorzichtig moet zijn met de implementatie van deze middelen. Het kan namelijk maar zo gebeuren dat door een fout er gehele pagina’s of categorieën uitgesloten worden van indexatie. Succes met het technisch goed zetten van jouw website!
Meer inspiratie opdoen? Bekijk ook eens dit artikel over crawlen en indexeren van ContentKing.




Bekijk de korte video's







Adverteren op Instagram & Facebook (Meta)
Meer wetenSocial media strategie
Meer wetenAI Update (archief)
Meer wetenSEO & GEO met AI
Meer wetenAI Marketing
Meer wetenAI Marketing
Meer wetenSEO & GEO met AI
Meer wetenOp zoek naar nog meer kennis?
-
De fase van gefragmenteerde focus door AI: de Hype Cycle zat er niet naast
-
Wat 100 Nederlandse websites onthullen over AI-zichtbaarheid [onderzoek]
-
Zo overtuig je mens én AI-agent op je website [+ checklist]
-
Pinterest laat zien waar AI-search écht naartoe gaat
-
Denk na over de volgende fase van digitale toegankelijkheid: bruikbaarheid boven vinkjes