
SEO automatiseren: het semantisch clusteren van zoekwoorden


Het semantisch clusteren van zoekwoorden is een onmisbaar onderdeel in zoekwoordenonderzoek. Maar het is wel vaak een tijdrovende en ingewikkelde taak. Gelukkig gaan ontwikkelingen in kunstmatige intelligentie gepaard met de opmars van tools en technieken die je helpen om dit werk te automatiseren. Zo pas je automatiseren toe zonder zelf het hoofd te breken over ingewikkelde code, zoals Python. Wat houdt automatisch clusteren in? Waarom clusteren we in eerste instantie zoekwoorden? Hoe zorg je ervoor dat je goed clustert? En vooral: waarom is dit zo belangrijk? In dit artikel geef ik antwoorden op deze vragen.
- Van Google Hummingbird tot MUM
- Waarom is semantisch clusteren van zoekwoorden relevant?
- Wat houdt het semantisch clusteren van zoekwoorden in?
- Het semantisch clusteren van zoekwoorden, hoe doe je dat?
- Automatisch zoekwoorden clusteren
- Is automatisch clusteren altijd beter?
- Zelf aan de slag met een tool?
Van Google Hummingbird tot MUM
In 2013 kondigde Google Hummingbird aan: de codenaam voor een nieuwe algoritme-update. Het omvat verschillende onderdelen, onder andere RankBrain. Hummingbird is in staat de semantiek van een zoekopdracht van een gebruiker te begrijpen. Het neemt de hele zoekopdracht – één woord of een hele zin – in overweging in plaats van losse woorden.
RankBrain
In 2015 kondigde Google RankBrain aan, een machinelearning-technologie en een verlengstuk van Hummingbird, die helpt zoekopdrachten nog beter te interpreteren. RankBrain is in staat patronen te zien tussen schijnbaar niet met elkaar gerelateerde zoekopdrachten en leert hoe ze op elkaar lijken.
RankBrain werkt samen met Hummingbird om betere zoekresultaten te geven voor zoekopdrachten van gebruikers. Alleen gaat Rankbrain verder dan semantisch zoeken. Het zelflerende algoritme is in staat om, op basis van wat het leert, deze ‘leerervaring’ toe te passen op toekomstige zoekopdrachten. Dit kunnen vergelijkbare zoekopdrachten zijn maar ook onbekende of combinaties van zoekopdrachten.
BERT
In 2019 introduceerde Google een nieuw algoritme update, genaamd BERT. Dit model gebruikt onder andere natuurlijke taalverwerking (NLP) en sentimentanalyse om elk woord in een zoekopdracht te begrijpen in relatie tot alle andere woorden in een zin.
MUM
En recent kondigde Google aan dat ze een nieuwe technologie ontwikkelen die 1000 x krachtiger is dan BERT: MUM.
“MUM is a technique that enables transferring knowledge across languages. MUM not only understands language, but also generates it. It’s trained across 75 different languages and many different tasks at once, allowing it to develop a more comprehensive understanding of information and world knowledge than previous models.” (Nayak, Google, 2021)
MUM is ook multimodal. Dit betekent dat MUM informatie van verschillende content-formaten, zoals webpagina’s, foto’s, video’s en meer, tegelijkertijd kan begrijpen.
“.. MUM is multimodal, so it understands information across text and images and, in the future, can expand to more modalities like video and audio.” (Nayak, Google, 2021)
Volgens Google zijn zoekmachines nog niet in staat zeer complexe zoekopdrachten in één keer op te lossen. Vaak ‘begrijpen’ de modellen niet de context of de gebruikersbehoefte achter een zoekopdracht. Dit resulteert in meerdere zoekopdrachten voordat in de gebruikersbehoefte is voorzien.
“People issue eight queries on average for complex tasks ….” (Nayak, Google, 2021)
Met MUM komt Google dichterbij om voor complexe vraagstukken direct antwoorden te geven. Denk bijvoorbeeld aan de “next query you’re going to type in”. Hiermee wil Google eigenlijk het antwoord op je 3e vraag al weergeven bij je eerste zoekopdracht. Latente behoeftes worden zo nog duidelijker, al tijdens de zoekopdracht van de gebruiker.
Het is voor Google’s modellen dus essentieel om te snappen wat iemands intentie is. En welke zoekwoorden diezelfde intentie en informatiebehoeftes hebben.
Waarom is semantisch clusteren van zoekwoorden relevant?
Twee (of meer) op het oog niet met elkaar gerelateerde zoekopdrachten kunnen dus inspelen op dezelfde informatiebehoefte en intentie van de zoeker. Hoe werkt dit in praktijk? Neem het volgende voorbeeld:
Zoekopdrachten 1 en 2
“Arabica koffiebonen”
“Robusta koffiebonen”
Op het eerste gezicht schuilen achter de zoekwoorden de volgende intenties en informatiebehoeften.
- Informatieve intent: informatie over wat Arabica / Robusta koffiebonen zijn (en waar je het eventueel kunt kopen)
- Commerciële / transactionele intent: kans is er dat Google Ads en Shopping-campagnes worden getoond
Als je deze zoekwoorden handmatig zou groeperen, enkel op basis van de syntax of de onderliggende betekenis, zou een mogelijke clusternaam “soorten koffiebonen” kunnen zijn. Er is een semantische relatie, maar heb je genoeg aan deze informatie als SEO-marketeer?
De zoekresultaten tonen vooral blogartikelen
De SERP (zoekresultatenpagina) laat zien dat de topresultaten in Google zo goed als worden gedomineerd door blogartikelen die inspelen op de vraag wat het verschil is tussen Arabica- en Robusta-koffiebonen:
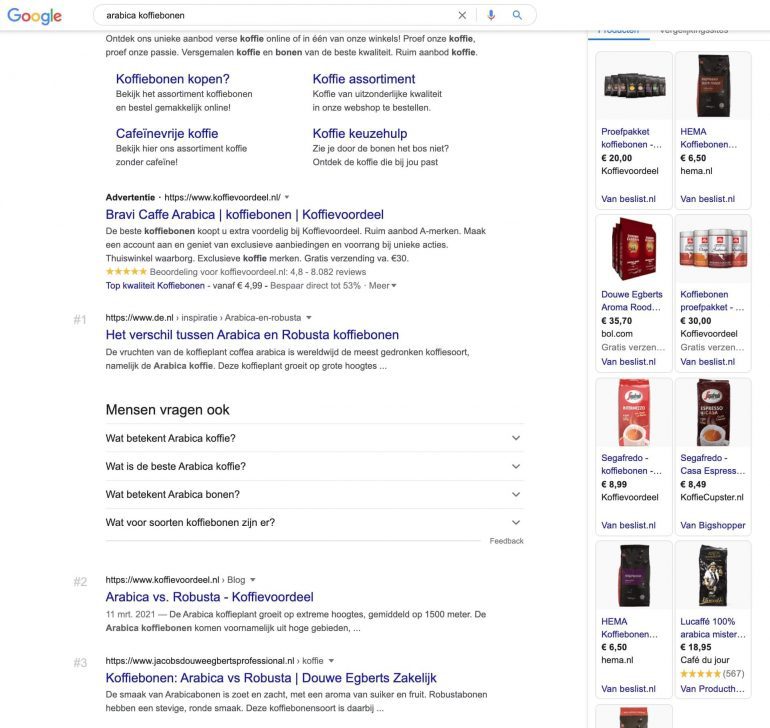
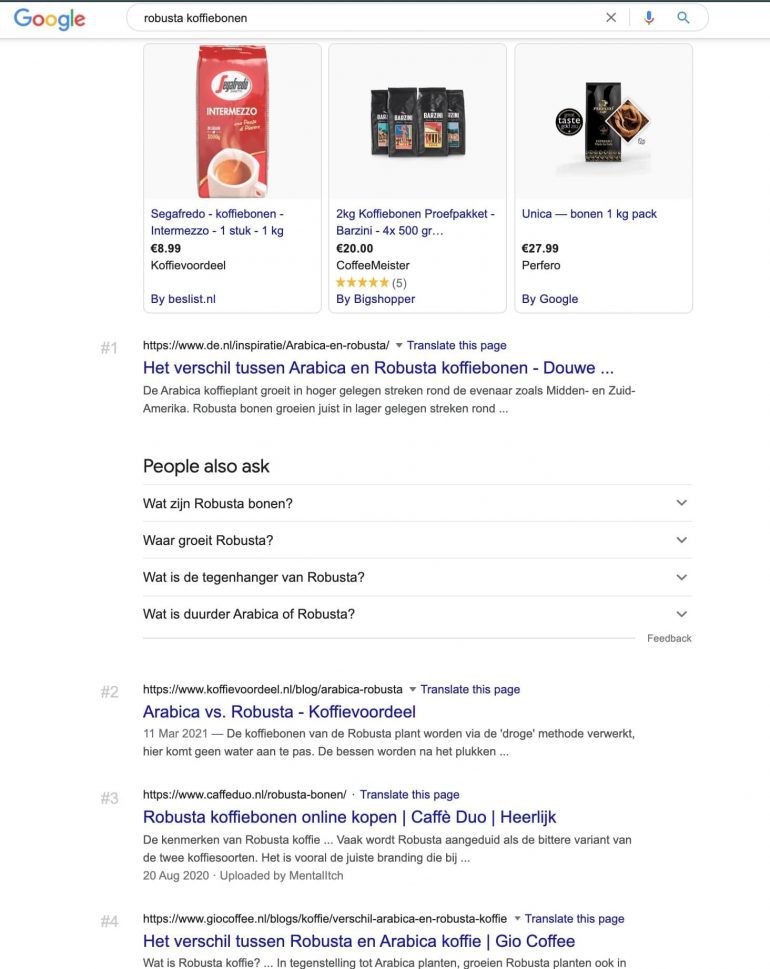
De semantische link is in eerste instantie duidelijk, maar zonder analyse had je wellicht over het hoofd gezien dat de intentie en informatiebehoefte van de gebruiker bij beide zoekopdrachten zo goed als hetzelfde is.
Dit is de kracht van RankBrain.
Ook wordt ingespeeld op de commerciële en transactionele intent door verschillende Ads. Op één URL na bevatten de organische zoekresultaten geen enkele URL die op deze intenties inspelen. Bijvoorbeeld, je ziet geen e-commercelandingspagina met een overzicht van Robusta (of Arabica) bonen. Blijkbaar overheerst de informatieve intentie en behoefte bij deze zoekopdrachten.
Denk na, voordat je content gaat maken
De bovenstaande inzichten had je waarschijnlijk alleen gekregen door de SERP voor elk zoekwoord apart te analyseren.
Je begrijpt ook dat er geen beginnen aan is om handmatig een analyse uit te voeren voor een zoekwoordenonderzoek van 5.000 of meer zoektermen.
Als SEO-consultant heb je als taak de juiste acties te verbinden aan de inzichten uit een zoekwoordenanalyse. Voor het maken van content wil je eerst gefundeerd op de volgende vragen antwoord kunnen geven:
- Welk type pagina’s (en functionaliteiten) vangen het best de zoekopdracht op?
- Welke intentie(s) heeft de zoeker?
- Welke expliciete en onderliggende latente vragen en behoeftes heeft de zoeker?
- Welke contentformats passen het beste bij het beantwoorden van de vragen?
En idealiter ook:
- Wie zoekt hierop? (wie is je doelgroep)
Voordat jij juiste acties kunt verbinden aan een zoekwoord, moet je dus eerst weten welke zoekwoorden in eerste instantie semantisch gerelateerd zijn en welke zoekwoorden inspelen op dezelfde intenties en informatiebehoeftes.
Het correct clusteren van zoekwoorden geeft je een ijzersterke start voor een contentstrategie. Je krijgt beter inzicht in hoe je pagina’s kunt organiseren en voor welke clusters van zoekwoorden je kunt ranken.
Wat houdt het semantisch clusteren van zoekwoorden in?
Het clusteren van zoekwoorden houdt in dat je zoekwoorden die semantisch gerelateerd zijn en inspelen op dezelfde zoekintentie clustert in een groep. Hoe werkt dit in de praktijk?
In 2017 schreef ik een artikel over ‘whisky voor beginners’ voor Gall & Gall. Ik was destijds een beginnende whiskydrinker en ging bij mezelf te rade om inzicht te krijgen wat de inhoud zou worden van het artikel. Ik stelde mijzelf de eerder genoemde 4 vragen:
- Welke type pagina (en functionaliteiten) vangen het beste de zoekopdracht op?
- Een blogartikel
- Welke intenties heeft de zoeker?
- Informatief en wellicht commercieel. De zoeker wil vooral weten welke whisky zij of hij kan proberen als beginnende whiskydrinker.
- Welke expliciete en onderliggende latente vragen en behoeften heeft de zoeker?
- Hoe weet ik of ik van whisky houd?
- Wat is lekkere whisky?
- Welke whisky is zacht?
- Ik snap niks van whiskyjargon, dus ik wil begrijpen wat ik lees
- Ik wil niet te veel geld uitgeven
- Waar begin ik?
- Welke contentformats passen het beste bij het beantwoorden van de vragen?
- Tekst, afbeeldingen en producten
Hieronder zie je de top 18 huidige rankings van het artikel zonder sitelink-rankings, 4 jaar later.
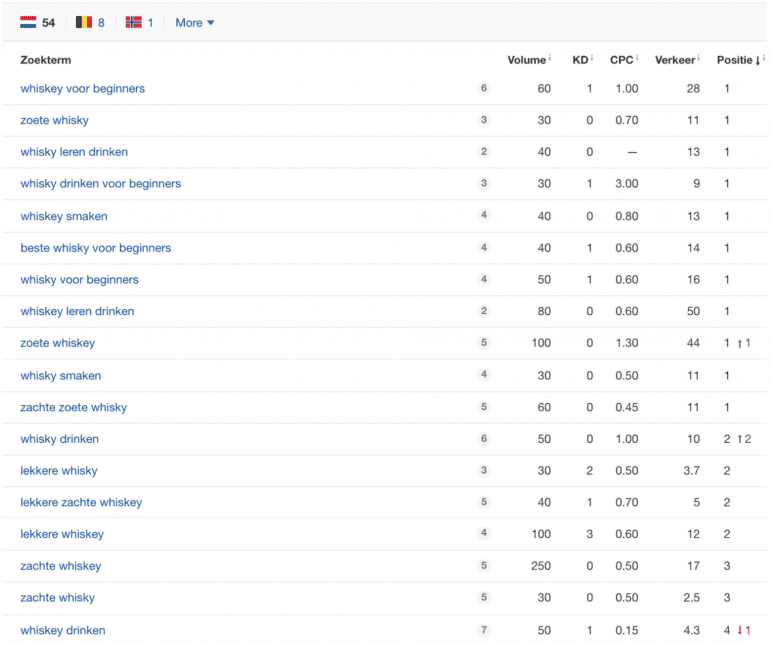
Wat valt op aan deze lijst en de inhoud van het artikel?
In eerste instantie het hoofdzoekwoord. ‘Whisky voor beginners’ wordt 0x genoemd. Is dit erg?
Nee.
Ik vergat destijds weleens om keywords in de tekst te plaatsen. In plaats daarvan hield ik mij bezig met de bovenstaande vragen.
Ook komen meerdere thema’s of topics voor in het artikel:
- Whisky voor beginners / beste whisky voor beginners
- Whisky leren drinken
- Whiskysmaken
- Zachte whisky
- Zoete whisky
- Lekkere whisky
- Combinatie van zachte / lekkere / zoete whisky
Wat maakt dat het artikel rankt op al deze termen in de top 3?
Grotendeels, omdat de semantische relatie en zoekintentie van de gebruiker bij alle termen ongeveer gelijk zijn. Daarnaast is het overkoepelende thema “whisky voor beginners”. Een beginner zoekt naar specifieke dingen waar een ervaren whiskydrinker simpelweg niet op zoekt.
Een beginnende whiskydrinker zoekt op zoete of zachte whisky, omdat dat de instapwhisky’s zijn. De overwegend makkelijk te drinken whisky’s. Het leren drinken van whisky doe je alleen als beginner. En de onderliggende informatiebehoeften zijn dat je wil weten hoe je begint en met welke whisky’s. “Whisky smaken” en “lekkere whisky” zijn typische zoekopdrachten voor iemand die weinig of niets van whisky af weet.
Google Search was met behulp van onder andere RankBrain in 2017 dus al in staat via het zelflerende algoritme de semantische relatie te bepalen tussen deze zoekopdrachten. Daarom rankt het artikel ook op zoekwoorden die niet per se terugkomen in het artikel, maar wel inspelen op de onderliggende intentie en informatiebehoefte.
Het correct clusteren van zoekwoorden geeft je een ijzersterke start voor een contentstrategie. Je krijgt beter inzicht in hoe je pagina’s kunt organiseren en voor welke clusters van zoekwoorden je kunt ranken.
Voordelen van semantisch clusteren
Andere voordelen van semantisch clusteren zijn:
- Sterkere rankings voor long-tail zoekwoorden
- Het beter begrijpen van de onderliggende relatie tussen clusters
- Verbeterde rankings voor short-tail zoekwoorden
- Meer mogelijkheden voor interne linking
- Opbouwen van expertise en autoriteit in een niche
Het semantisch clusteren van zoekwoorden, hoe doe je dat?
Zoekwoordenclustering begint uiteraard met een zoekwoordenonderzoek. Verzamel zoveel mogelijk relevante zoektermen inclusief alle variaties, long-tail zoekwoorden en subtopics.
Zorg bij het creëren van een zoekwoordenlijst ervoor dat je relevantie en zoekintentie als leidraad neemt. Je wil natuurlijk alleen tijd en budget spenderen aan content die relevante bezoekers naar de site brengt. Het kan een flinke klus zijn om te bepalen waarom een zoekopdracht nu precies relevant is. Zeker gezien relevantie een veelgebruikt buzzword is.
Verbeter de nauwkeurigheid van je zoekwoordenonderzoek
De volgende factoren helpen om de scope te verkleinen en de nauwkeurigheid van zoekwoordenonderzoek te verbeteren:
- Het type website. Is het een inspiratieplatform? Of een nieuwssite? Een e-commerceplatform? Of een combinatie?
- De partijdigheid of onpartijdigheid van de site. Verkoop je bijvoorbeeld 1 merk met eenzelfde product of verschillende producten? Of heb je een vergelijkingssite die verschillende merken host?
- B2B of B2C. Ben je actief in B2B of B2C, of wellicht beiden?
Afhankelijk van deze factoren kunnen bepaalde zoekopdrachten wel of juist niet worden opgevangen door een site.
Het type pagina en contentformats spelen ook een rol
Daarnaast spelen ook het type pagina en contentformats een rol in het begrijpen van de informatiebehoeften. Sommige zoekopdrachten kunnen bijvoorbeeld alleen worden opgevangen met een bepaald type pagina en contentformat. Dit hangt af van hoe de gebruiker content wil zien en consumeren.
Een voorbeeld
Stel je bent als SEO-marketeer ingehuurd voor het denkbeeldige fietsmerk SnelFietsie. Het fietsenmerk heeft een eigen platform met webshop. Je hebt het zoekwoord “fiets kopen” gevonden in het zoekwoordenonderzoek. Is dit zoekwoord relevant?
Nee.
De top zoekresultaten in Google tonen gevestigde partijen die:
- Verschillende merken verkopen
- Met landingspagina’s ranken met een overzicht van een groot aanbod aan fietsen en merken
- Zowel producten aanbieden als extra informatie verschaffen
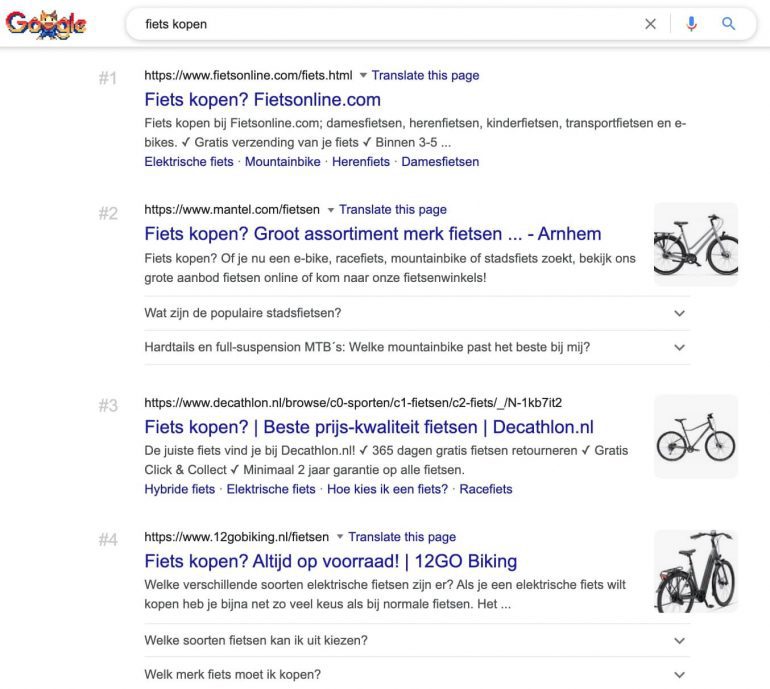
Mensen die zoeken op “fiets kopen” overwegen een fiets te kopen, maar hebben nog niet een bepaald merk voor ogen. Het voelt logisch om een overzicht te zien van verschillende merken en fietsen met bijbehorende content die inspeelt op eventuele expliciete en latente vragen.
Het is aannemelijk dat SnelFietsie als individueel fietsmerk niet kan inspelen op deze informatiebehoefte en intenties. Een relevante pagina is daarom ook buiten het bereik van SnelFietsie.
Begrijpen welke zoekwoorden op basis van deze factoren wel of niet relevant zijn, is essentieel om de juiste contentclusters te maken en dus relevant verkeer naar de website te sturen.
Automatisch zoekwoorden clusteren
In toenemende mate verschijnen AI-gedreven keyword clustering tools, die in minuten een lijst van duizenden zoekwoorden analyseren en semantisch groeperen. Het nadeel van de meeste, vaak gratis, tools is dat de technologie achter het clusteralgoritme is gebaseerd op taal. Groepen of clusters worden gedefinieerd op basis van corresponderende termen tussen de verschillende zoektermen in de lijst van zoekwoorden. Het is een relatief onnauwkeurige methode om zoekintentie en semantische relaties in kaart te brengen.
De meeste betaalde tools gaan een stap verder door ook de SERP-resultaten van elk individueel zoekwoord als factor mee te nemen in het algoritme. Door naar de zoekresultaten in de SERP te kijken, kunnen per individueel zoekwoord zoekintenties worden afgeleid. Daarnaast is het ook mogelijk om semantische relaties te ontdekken door alle SERP URL-rankings van de gehele set zoekwoorden met elkaar te vergelijken.
Algoritmes met eigen variabelen
Elke tool houdt er een eigen ontwikkelde algoritme op na die verschillende variabelen gebruikt om semantiek en intentie te bepalen. Zo helpen variabelen te bepalen of er een semantische relatie is en, zo ja, hoe sterk, welke intenties een zoekwoord heeft en in welke clusterschil of -laag een zoekwoord terecht komt.
Een aantal voorbeelden van variabelen kunnen zijn:
- Semantiek – Het vergelijken van het aantal overeenkomende URL’s in de top X van de SERP
- Semantiek – Het aantal overeenkomende rootdomeinen in de top X van de SERP
- Intentie – Het aanwezig of afwezig zijn van Google Ads
- Intentie – het signaleren van bepaalde woorden die intentie vrijgeven (bijvoorbeeld “kopen”)
- Intentie – het signaleren van SERP-features
- Schil – optimale kleine clusters samenvoegen die samen in groepen die meeste semantische overlap hebben
Het nadeel van clusteren op basis van taal
Clusteren op basis van taal blijft wel een nadeel. Je kunt namelijk niet makkelijk schakelen tussen talen of landen. Ook bots je op tegenstrijdigheden. Bijvoorbeeld: “huis kopen” betekent niet alleen dat je gelijk een huis wil kopen. Je wil ook informatie rondom het proces van een huis kopen.
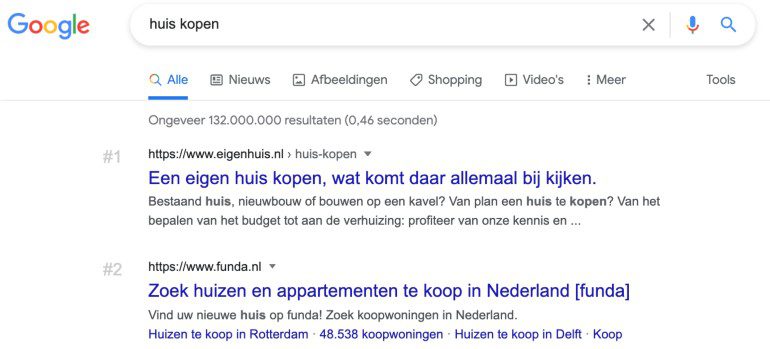
Wanneer kies je voor automatisch semantisch clusteren?
Het automatisch semantisch clusteren van zoekwoorden staat of valt bij de kwaliteit van het algoritme, de flexibiliteit van de tool en de tijdswinst die je ermee behaalt. De flexibiliteit om bijvoorbeeld per regio of taal een zoekwoordenset te kunnen clusteren. Dit betekent dat de clustering van je zoekwoorden semantisch is gegroepeerd op basis van de lokale zoekresultaten en de vooraf ingestelde taal. Of het gemak om in 10 – 20 minuten een gehele set van zoekwoorden geclusterd te krijgen.
Maar automatische oplossingen voor semantisch clusteren zijn vooral inzetbaar als de clustering van betere kwaliteit is dan handmatig clusteren. Tijdwinst is dus mede afhankelijk van de clusteringkwaliteit. Het heeft weinig zin als je zelf nog uren bezig bent met het corrigeren van clusters. Tijdswinst en flexibiliteit zijn dus geen automatische voorwaarde om een tool te gebruiken.
Wat levert automatisch clusteren van zoekwoorden wel op als de kwaliteit goed genoeg is?
- Clusters zijn data-gedreven en gebaseerd op aannames of gevoelsmatige clustering
- Het elimineert fouten in clusteren, met name als een tool niet taalafhankelijk is
- Je hebt een set van clusters en subclusters binnen enkele minuten
- Je maximaliseert het aantal zoekwoorden om voor te ranken
- Geen irrelevante zoekwoorden meer in eenzelfde cluster
- Direct inzicht in gebruikers intenties voor zowel individuele zoektermen als (sub)clusters
- Direct inzicht in de zichtbaarheid van je domein voor zowel zoekwoorden als (sub)clusters
Is automatisch clusteren altijd beter?
Dit hoeft niet het geval te zijn.
Werk je aan een zoekwoordenanalyse met 200 zoekwoorden? Dan is handmatig clusteren een goed alternatief. Alhoewel in praktijk het aantal zoekwoorden meestal in de duizendtallen ligt voor SEO-marketeers werkzaam bij MKB en grootbedrijven. Juist bij deze bedrijven bepalen de bestaande werkprocessen en de set van SEO-tools mede in hoeverre een nieuwe tool wordt geadopteerd. Bedrijven werken al met bestaande templates in Google Spreadsheets, dashboards en Excel-documenten voor processen zoals keyword-analyses en contentplanningen. In sommige gevallen zelfs met eigen ontwikkelde software. Een overstap naar een andere of extra werkwijze en tool is dan niet in alle gevallen gewenst.
Ook vervangt een automatisering niet gelijk de analyse. Automatisch clusteren zorgt ervoor dat jij meer tijd overhoudt voor inzichten vergaren, acties opstellen en strategieformulering. Op de knop drukken, achterover leunen en afwachten: dat levert natuurlijk ook niks op. Automatisering geeft een boost aan je productiviteit, het is geen vervanger voor activiteit.
Zelf aan de slag met een tool?
De volgende vragen helpen je te bepalen of een tool of service die automatisch clustering aanbiedt kwalitatief genoeg is:
- Is de tool taalonafhankelijk?
- Heb je de flexibiliteit om te schakelen tussen taal, land en regio?
- Kijkt de tool naar de SERP-resultaten om intentie en semantiek te bepalen?
- Kun je intentie per zoekwoord of (sub)cluster observeren?
- Komen jouw handmatige checks in de SERP overeen met de uitkomsten van de tool?
- Kun je actiegerichte inzichten halen uit de output van de tool?
De volgende vragen helpen je te bepalen of een tool of service die automatisch clustering aanbiedt past bij jouw dienstvorm of organisatie:
- Is de flexibiliteit aanwezig om werkprocessen in te richten rondom de tool?
- Biedt de tool exclusief software voor semantisch clusteren of is het onderdeel van een reeks producten van een SEO-tool?
- Welke data moet je aanleveren en welke data en inzichten krijg je opgeleverd?
- Wat zijn de beperkende factoren van de software voor jouw organisatie?
Heb je vragen over het semantisch clusteren van zoekwoorden? Stel ze gerust via de reactiemogelijkheid onder dit artikel.
Dit artikel is gecheckt door het SEO-panel.



Bekijk de korte video's








Napkin AI: de tool die jouw tekst omzet naar ijzersterke visuals
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenSocial media strategie
Meer wetenAI Update (archief)
Meer wetenSEO & GEO met AI
Meer wetenAI Marketing
Meer wetenAI Marketing
Meer wetenSEO & GEO met AI
Meer wetenOp zoek naar nog meer kennis?
-
1 op de 5 Nederlandse websites blokkeert AI-zoekmachines zonder het te weten
-
Wat het Digital News Report 2026 betekent voor de toekomst van overheidscommunicatie
-
Meta, Google en Wall Street zetten in op voorspellingsmarkten. Moet jij ook opletten?
-
Van online winkel naar AI-infrastructuur: de transformatie van de webshop
-
Waarom bezoekers afhaken terwijl ze wél geïnteresseerd zijn



