Big data for tiny services: de 3 lagen van een datastrategie


De waarde van data ontstaat door verbanden inzichtelijk te maken en deze vervolgens toe te passen in de dienst die aan de eindgebruiker wordt aangeboden. Om dit goed te doen kun je het beste gebruik maken van drie verschillende lagen. Deze lagen zorgen ervoor dat er een goede balans ontstaat tussen het verzamelen van informatie van de gebruiker en het toepassen van deze kennis in persoonlijke, relevante diensten.
Big data for tiny services
Ik noem dat big data for tiny services. Hierbij maak ik een onderscheid in onderstaande drie lagen.
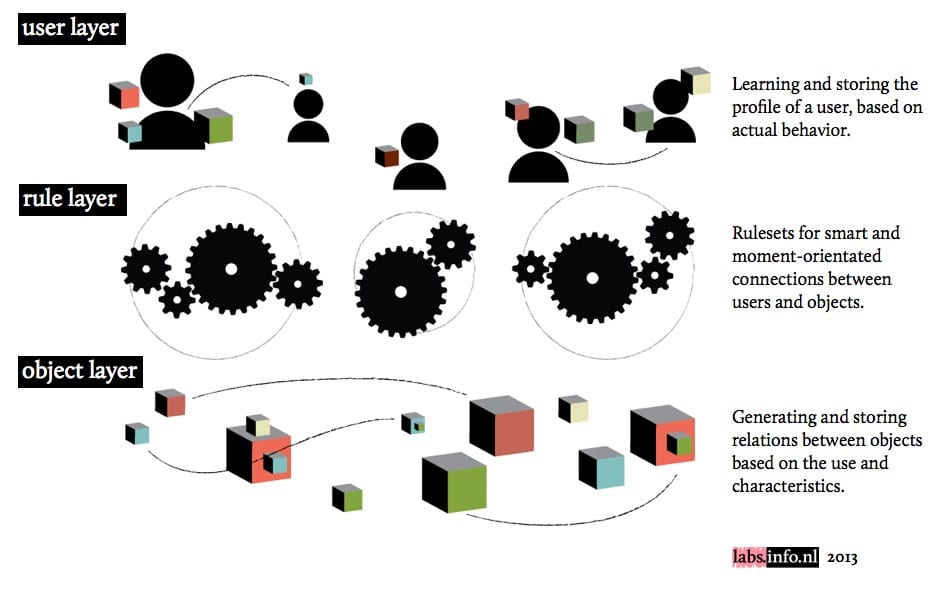
Model van 3 lagen Big Data for Tiny Services
1. De laag van de dataobjecten
De eerste laag is die van de dataobjecten. De objecten worden door het gedrag van gebruikers aan elkaar gekoppeld en daarnaast ook door de eigenschappen van objecten (meta-informatie). Elk object krijgt alle relaties toegewezen die voortkomen uit het gedrag, waarbij verschil in zwaarte van de relaties ontstaat door de frequentie. Ook negatieve relaties kunnen onderdeel zijn van de objectrelatie.
Denk bijvoorbeeld aan een online shop waar de producten door het koopgedrag aan elkaar worden gelinkt. Welke producten komen vaak bij elkaar in een mandje terecht? En welke combinaties van meer dan twee komen voor? Zijn er verbanden tussen bepaalde gebruikers die altijd dezelfde productcombinaties kopen? Maar ook: link de producten die vaak worden bekeken en gekocht aan van de producten die alleen worden bekeken en nooit worden gekocht. En kijk nog een stap verder: link producten die altijd in de middag worden gekocht aan producten die alleen in de avond worden gekocht. Et cetera. Voeg daaraan op dezelfde manier een laag toe van verbindingen van productsoorten, merken, prijscategorieën en eigenschappen die nog meer te koppelen zijn aan producten.
2. De laag van de gebruiker
De tweede laag is die van de gebruiker. De gebruiker geeft door zijn gebruik van de objecten informatie mee aan de objecten, maar de tweedegraads objectrelaties worden niet vast aan de gebruiker gekoppeld: als object 1 vanuit de objectrelatie aan object 2 is gekoppeld en object 2 aan de gebruiker is gekoppeld, betekent dit niet automatisch dat object 1 ook aan de gebruiker is gekoppeld. Het profiel van de gebruiker blijft zuiver op zijn eigen gedrag. Uitsluitingen worden uiteraard ook opgeslagen. Naast objecten worden ook relaties met andere gebruikers vastgelegd. Ook hier weer alleen op de eerste graad.
In hetzelfde voorbeeld van de shop begint het met alle kopers die een account hebben. Welke producten hebben ze gekocht en welke producttypen? Zorg ook voor mechanismes waarin meer expliciete keuzes te ontdekken zijn. Eem collaborative filtering-systeem suggereert gelijksoortige producten op basis van de productlaag. Als de gebruiker een product wel kiest/bekijkt uit een selectie maar de andere niet, is het vooral ook interessant vast te leggen welke niet worden gekozen.
3. De laag van de terugkerende intelligentie
De derde laag bevat de terugkerende intelligentie. De wijze waarop waarop objecten aan gebruikers worden gekoppeld gebeurt ad-hoc, maar een aantal algoritmes kunnen de basis zijn. Doordat deze regels los staan van zowel objecten als gebruikers kan slimmer worden geprofileerd.
In het voorbeeld kan naast de eigenschappen van bekende gebruikers ook anoniem bezoekersgedrag worden vastgelegd. Cluster op type zoeken, duur op de website, aantal producten dat wordt bekeken tot een koop, et cetera. Deze clusters kunnen weer eigen correlaties hebben met de productlaag en de gebruikerslaag. Bij het bezoek aan de online shop wordt de gebruiker op basis van zijn gedrag gekoppeld aan een van de clusters. Elk cluster wordt voorzien van regels die het gedrag van de website bepalen (welk aanbod zetten we naar voren), maar ook: hoe spreken we de bezoeker aan en wat is de volgorde van bijvoorbeeld achtergrondinformatie over kopen of koopadviesmodules?
Deze regels zijn natuurlijk ook gekoppeld aan de bekende bezoekers. De regels worden specifiek daarvoor gemaakt, want de bekende bezoekers vragen uiteraard een speciale behandeling. De toepassing van deze lagen is op instant basis. Per gebruiker wordt een combinatie gemaakt van kennis over zijn interesses, uitsluitingen, en gecombineerd met de regels worden suggesties gedaan. Deze suggesties nodigen gedrag uit en dit gedrag heeft een extra waarde in de kennis op elke laag.
Stappenplan van een datastrategie
Hoe kom je nu tot een afgewogen en toch praktische datastrategie? In hoofdlijnen neem je de volgende stappen:
1. Begin met verzamelen
Niks houd je tegen alle data die ontstaan ook op te slaan. Ook als nog niet precies duidelijk is waarvoor: gewoon opslaan. Sla deze data ongestructureerd op om zoveel mogelijk vrijheid van toepassing te houden. Wees creatief in het vinden van datastromen. Kijk hiervoor naar technologieën als Hadoop die hier specifiek voor geschikt zijn. Dit kan ook prima naast een bestaande datastructuur worden opgezet (bijvoorbeeld CRM), waar na verloop van tijd de koppelingen worden gelegd.
 2. Formeer een datateam
2. Formeer een datateam
Combineer de verschillende disciplines bij de datascientist of bij verschillende specialisten met een gemeenschappelijk gevoel bij data. Kennis van de gebruiker en de business en creativiteit in content en techniek zijn belangrijke eigenschappen.
3. Leg de verbanden
Eerste stap van het team: zoek de verbanden tussen datastromen. Zowel binnen de eigen datastromen als de externe. Sta open voor onverwachte verbanden, sterker nog: de onverwachte verbanden moeten bewust worden opgezocht. Hiermee zal uiteindelijk meer waarde worden bereikt.
4. Visie ontwikkelen
Ga op zoek naar de waarde van het toepassen van data voor de diensten. Formuleer dat in een dataconcept en visie, het punt op de horizon: kijk verder dan het cross-sellen van producten of het beter kennen van de doelgroep. Dat moet ook, maar waar ligt de diepere waarde?
5. Strategie bepalen
Reflectie en iteratie. Als het concept met de datastromen wordt gecombineerd, zijn er dan nog missende delen? Scherp het concept aan. Vervolgens wordt in de strategie bepaald hoe met de data de visie bereikt kan worden. Stap voor stap. Begin met een datapunt dat veel dynamiek kent en waarmee een onderdeel van de hele dienst op zichzelf slim kan worden gemaakt. Een adviesmodule of een slimmere collaborative filter.
6. Learn and launch
Stapsgewijs uitrollen. Begin dus met een datapunt en leer van de resultaten. Pas dan aan, scherp aan en ga verder. Kijk goed naar de statistieken, maar waardeer daarin niet alleen de grote uitschieters, probeer juist ook de middengroep te analyseren op typisch gedrag. En doe kleine experimenten om hypotheses te toetsen. Vergeet niet de organisatie mee te nemen in de resultaten.

Aandachtspunten voor een goede datastrategie
Tot slot nog een aantal aandachtspunten op een rij:
Ga voor de delta
Liever minder datapunten die veranderen dan veel datapunten die statisch zijn. De verandering in gedrag is hetgeen waar je het meeste kennis uit kunt halen. Tijd is een belangrijke dimensie in een datastrategie.
Mix moment en inzicht
Ontwerp de profilering zo dat het profiel en de relaties die daaruit volgen op het moment van gebruik wordt gemaakt, en spiegel die met de laatste stand van de inzichten. Blijf altijd beseffen dat gedrag heel verschillend kan zijn per gebruik, motivaties kunnen verschillen. Het is niet in beton gegoten.
Wees nederig
Plaats mensen dus niet in hokjes en dring ze geen keuzes op. Doe suggesties, ga de dialoog aan. Ook hier geldt dat negatieve ervaringen beter worden onthouden dan positieve. Kleine suggesties en verbanden leggen, geen invulling voor de klant doen.
Creëer serendipiteit
Vergeet niet te verrassen en soms uit het profiel te stappen. Als het aanbod steeds relevanter wordt zal het profiel steeds minder waardevol worden doordat er geen ijking is aan de wensen. Leren gaat altijd door en dat moet je stimuleren met impulsen.
Leer en pas aan
Verras ook jezelf, blijf openstaan voor nieuwe inzichten en pas die toe. Ga actief achter de knoppen zitten en wees bewust van wat je ziet optreden. Maak op basis daarvan nieuwe varianten om te proberen en te leren.
Combineer bronnen
Gebruik niet alleen de eigen data, maar maak een snelle start met de vele bestaande databronnen, veelal uit social media. Maar ook partners waarmee data barter deals zijn te sluiten kunnen interessant zijn. Toets deze wel goed en probeer ze zo ruw mogelijk beschikbaar te krijgen voor het eigen systeem.
Intern draagvlak
Zorg voor intern draagvlak, koppel resultaten terug naar de organisatie en inspireer om mee te doen in de ontwikkeling van nieuwe datatoepassingen.
Ga beginnen
Data vasthouden is de start. Wacht er niet mee.
Formeer een team dat verschillende disciplines in zich heeft. Wees creatief in het toepassen van de data. Start met een dynamisch veranderend datapunt en bouw verder uit. Dan is de stap naar het toepassen zo klein mogelijk – en daarmee is het bewijs van een effectieve datastrategie geleverd.



Bekijk de korte video's










Canva met AI
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenSocial media strategie
Meer wetenDe nieuwe SEO- & GEO-spelregels: scoren in Google én AI-search
Meer wetenAI Update (archief)
Meer wetenSEO-copywriting met AI
Meer wetenSEO & GEO met AI
Meer wetenCommunicatie & AI
Meer wetenContent maken met AI
Meer wetenZo check je in 5 stappen hoe zichtbaar je bent in AI Overviews
Meer wetenOp zoek naar nog meer kennis?
-
5 onverwachte bijwerkingen van AI die organisaties nu al voelen
-
Je profielgrid eindelijk zelf herordenen & 4 andere Insta-updates
-
83% van het MKB is onzichtbaar voor AI en merkt het niet eens
-
De GDMA Email Benchmark 2026: Nederland mailt sterk, zo bouw je daarop voort
-
Deze 5 rollen bepalen het succes van je AI-implementatie