Dit moet je als marketeer weten over het klantdatamodel


Data is waardevol bij het maken van de best mogelijke beslissingen. Als marketeer kan het je daarom voordeel opleveren om te weten wat een klantdatamodel is en hoe het in elkaar zit. Namelijk, structuur in data aanbrengen is de basis van je data-gedreven marketinginspanningen. Ook draagt het bij aan het nemen van beslissingen. Ook al maak je als marketeer deze modellen vaak niet, basiskennis is handig bij gesprekken over marketingproducten met dataspecialisten. Ik help je in dit artikel op weg.
Het ontwikkelen van een klantdatamodel is een van de 5 fundamenten voor het gebruiken van een moderne datastack en het automatiseren van analytics. De andere 4 fundamenten zijn
- datacollectie, inclusief het verzamelen van events
- visualisatie van performance
- het voorspellen van gedrag
- het activeren van de beslissingen
Je kunt data alleen bruikbaar maken voor je teams en je systemen door een klantdatamodel te maken. Dit is het tweede fundament na datacollectie. Een voorwaarde hiervoor is dat je de klantdata in ruwe vorm tot je beschikking hebt in je data warehouse of data lakehouse.
Een data warehouse is een database voor het centraal opslaan en verwerken van gestructureerde data uit verschillende onderliggende databases. Bij een data lakehouse worden alle soorten gestructureerde en ongestructureerde data in allerlei vormen (ook bestanden, beelden of berichten) in originele vorm opgeslagen. Een data lakehouse combineert beiden.
Goede informatie- en dataarchitectuur
De bruikbaarheid is afhankelijk van een goede informatie- en dataarchitectuur. Heb je vooraf geïnvesteerd in een goed ontwerp, dan zal je dat direct helpen bij het leggen van verbanden tussen datapunten en bij het krijgen van inzicht! Het beste kun je dit doen door de ruwe gegevens in bruikbare modellen of objecten te organiseren die geschikt zijn voor de betreffende business use cases. Hierbij zijn 2 hoofdcomponenten belangrijk:
- Identity Resolution: het identificeren van dezelfde gebruikers in verschillende gegevensbronnen, afkomstig uit verschillende systemen.
- Master Data Model: het realiseren van een definitief/zuiver beeld van je klanten en bijbehorende feiten en dimensies.
Het advies om mee te starten is dat je het beste zo klein mogelijk kunt beginnen in de meeste gevallen. Het incrementeel opbouwen van modellen en snelle iteraties leveren je snel echte waarde op. Een benadering die ik vaak toe pas, en die goed werkt, is door te beginnen met het maken van de business objecten die nodig zijn om groei binnen marketing en sales te realiseren: klanten, transacties en events.
Herkennen van klanten over meerdere kanalen met identity resolution
De eerste stap begint bij het maken van een identity graph van klanten en gebruikers. Hiermee leg je de relatie tussen dezelfde gebruikers binnen je owned, paid en earned kanalen en applicaties. Zo werk je naar een uniek klantrecord, ook wel ‘global customer ID’ toe (dit wordt ook wel “stitching of linking” genoemd).
Hieronder een Entity Relationship Diagram dat de relatie legt tussen klanten en onbekende gebruikers in een voorbeeldimplementatie. Dit is een vereenvoudigde weergave.
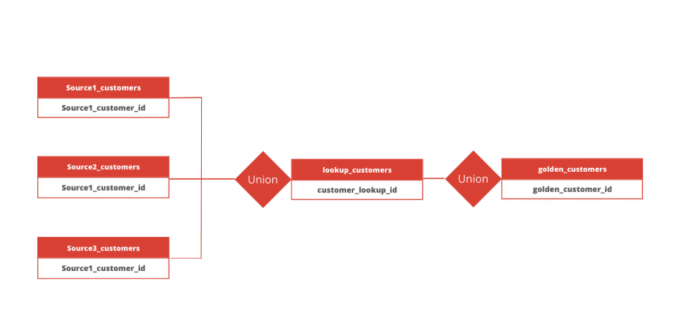
De 3 belangrijkste stappen voor een eenvoudige identity resolution, gebaseerd op SQL in je data warehouse:
1. Identificeer match keys
Je identificeert match keys om te bepalen welke velden en kolommen je gaat gebruiken. Hiermee bepaal je welke personen, of andere onderdelen van het bedrijf hetzelfde zijn binnen en tussen bronnen. Een typisch voorbeeld van een match key is een e-mailadres en een achternaam.
2. Aggregeer klantrecords
De tweede stap is het maken van een bron lookup-tabel die alle klantrecords uit de brontabellen bevat.
3. Matchen en een uniek klant-ID toekennen
Als laatste stap neem je records die dezelfde match keys hebben en die samen een unieke klant identifier genereren voor deze groep klantenrecords. We noemen dit een klant-ID. Ieder klant-ID dat je genereert kun je gebruiken om de klantbronnen aan elkaar te koppelen als onderdeel van een datastrategie.
Hoe dit er in de praktijk uitziet beschrijf ik in een artikel op Frankwatching over first-party datastrategie in de kop “first-party data gebruiken in een CDP”. Als je meer bronnen toevoegt, kun je ze hetzelfde proces laten doorlopen door de juiste regels en prioriteiten voor de bron in te stellen.
Het maken van master datamodellen voor een centraal klantbeeld
Om je eerste klantbeeld te creëren heb je je eerste probleem, dat te maken heeft met het vaststellen van de identiteit van de klant, opgelost met identity resolution. Daarna kun je de data pipelines of ETL-processen (laten) opzetten om de mastermodellen te bouwen.
Om snel waarde te creëren, raad ik je aan om te beginnen met een Klant →Transactie →Event framework. Dit framework maakt de 3 belangrijkste objecten van je brongegevens. De afbeelding hieronder laat zien hoe dit type modelleren eruit ziet.
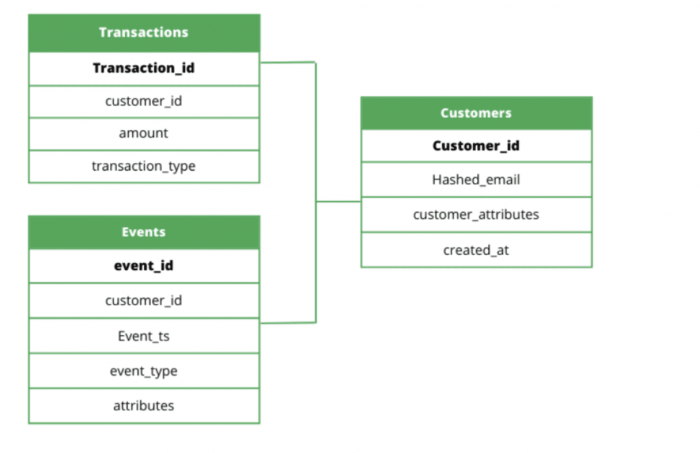
Klanten: tabel van je klanten met de mogelijkheid om snel nieuwe velden toe te voegen.
Transacties: join key, dat is de relatie leggen, van de customertabel naar de klant transactie-historie, inclusief productretouren van een e-commerce bedrijf bijvoorbeeld.
Events: ieder event dat je volgt van iedere customer.
Als je organisatie een marketplace is of verschillende bedrijfsidentiteiten heeft, kun je deze stamdatamodellen wijzigen om te volgen wat zinvol is. Bijvoorbeeld, voor een marktplaats ‘met twee kanten’ zoals bol.com en Marktplaats, zou het kunnen dat je tabellen hebt voor zowel verkopers en kopers als verschillende entiteiten. Voor een B2B-business heb je waarschijnlijk verschillende accounts en contactentiteiten in de hiërarchie.
Tools voor datacollectie en -transformatie
Er zijn verschillende manieren om data te verzamelen en om bruikbaar te maken het data warehouse. Bruikbaar maken wordt datatransformatie genoemd. In de meeste gevallen adviseer ik het analyticsteam om te kiezen voor een op open source-gebaseerde oplossing.
De afgelopen jaren hebben open-sourcetools voor het creëren van de moderne klantdatastack / CDP het beheer en onderhoud van data steeds makkelijker gemaakt en daarnaast de kosten aanzienlijk verlaagd.
Basiskennis van datamodelling is handig
Het creëren van een klantdatamodel is een van de 5 funderingen van een moderne datastack. Als datagedreven marketeer is het handig om basiskennis van datamodelling te hebben. Dit artikel is waarschijnlijk wat technisch, maar het geef je een indruk wat er bij komt kijken. Zo kun je een betere gespekspartner zijn als je aan tafel zit met data-engineers en -analisten.