
Succesvol datagedreven werken? Dit moet je aan- & afleren


Van nieuwe mogelijkheden worden mensen enthousiast én huiverig. Dat zien we ook rond datagedreven werken en digitalisering. Berichtgeving is jubelend over wat er mogelijk wordt en ‘zelfs al kan’ óf staat bol van de wantrouwige hyperbolen. De waarheid ligt in het midden, zeker rond maatschappelijke opgaven. In elk geval is een transitie naar datagedreven werken meer dan een dashboard implementeren en gaan met die banaan! In dit artikel schets ik de uitdagingen en benoem ik vaardigheden en ingesleten patronen die bestuurders, beleidsmakers en uitvoerders moeten aan- of juist afleren.
Van wondere wereld naar dagelijkse praktijk
De ogen van de mens schitteren als er nieuwe mogelijkheden opkomen aan de horizon. En dit terwijl die mogelijkheden misschien niet eens een directe behoefte vervullen. Toch hoeft dat gebrek aan toepassingen niet een probleem te zijn. Het kinderlijke enthousiasme van de voorvechters zorgt voor energie en beweging, en zet belangrijke innovaties in gang.
Tot de verbeelding spreken bijvoorbeeld robotisering en kunstmatige intelligentie – vooral in combinatie. Van Bassie en Adriaans ‘Robin’ (of: “die kutwekker”, zoals mijn vriendin ‘m liever noemt) tot alle incarnaties van de Terminator – in ieders geheugen staat wel een voorbeeld uit de fictie gegrift. Tegenwoordig komen we ze steeds meer tegen. Gewoon in onze leefomgeving: Alexa helpt je boodschappen doen en de zelfrijdende Tesla brengt je thuis na een met wijn besprenkeld diner.

De oer-zelfrijdende auto: KITT uit Knight Rider.
Oplossen van sociale vraagstukken: beleidsmakers zijn ‘data woke’
Hoezeer een zelfrijdende auto ook tot de verbeelding spreekt, als ik eerlijk ben vind ik kunstmatige intelligentie in consumentenproducten minder interessant. Liever denk ik aan de maatschappelijke kansen voor datagedreven werken. Dat die er liggen, ziet ook de overheid. Steeds meer beleidsmakers zijn ‘data woke‘. Ze geloven in de waarde van data voor beleidsontwikkeling, dienstverlening en uitvoering van overheidstaken, toezicht en handhaving, en de bedrijfsvoering. En misschien wel belangrijker: voor sociale innovatie en het oplossen van taaie maatschappelijke vraagstukken. Denk aan de energietransitie en het tegengaan van ondermijning.
Dat leidt onder meer tot initiatieven als de Data Agenda Overheid, bedoeld om “in samenwerking het delen, combineren en de analyse van data te bevorderen”. Een snelle blik op de vijf pijlers van de agenda laat zien dat de overheid zich realiseert dat daar randvoorwaarden bij horen. Ethische overwegingen en ‘publieke waarden’ krijgen aandacht, naast het verbeteren van de kwaliteit van data. Ook investeert de overheid in mensen, organisatieontwikkeling en cultuurverandering rondom datagedreven werken.
Veel mensen zien een algoritme als de duivel
Ondanks dat bewustzijn blijkt datagedreven werken niet altijd vlekkeloos te verlopen. Met name de inzet van algoritmes haalt regelmatig de media – en meestal niet in positieve zin. Rond de opsporing van fraude zijn verschillende (overheids)organisaties breed uitgemeten onderuitgegaan. Ze koppelden data en voorspellende rekenmodellen aan ‘risicoprofielen’ en trokken onterechte conclusies over mogelijke misstanden.
Door dat soort berichten blijft er voor veel mensen een zwavelgeurtje hangen rond algoritmes en datagedreven werken. Of dat terecht is, is de vraag. Niet de ontwikkelingen rond kunstmatige intelligentie en digitalisering zélf zijn immers per definitie gevaarlijk. Het venijn zit in hoe organisaties hiermee omgaan. Uiteindelijk zijn zij de drijvende kracht achter onwenselijke situaties, door onhandig of soms ronduit onethisch te handelen. Dat blijkt vaak – zoals in het schrijnende voorbeeld van de Belastingdienst en de kinderopvangtoeslag – een beslissing van aanwijsbare mensen.
Fictie weerspiegelt de werkelijkheid (spoiler alert!)
Na het lezen van zijn briljante, dystopische roman De Onvolmaakten (2020) bekruipt je het gevoel dat schrijver Ewoud Kieft als een vlieg op de wand van zo’n bestuurskamer heeft gezeten. Hij laat zien dat het inderdaad mensen zijn die ontsporen, en hoe vanzelfsprekend dat gebeuren kan.
In een samenleving geleid door ‘het Conglomeraat’ worden mensen begeleid door een algoritme: Gena. Zo ook hoofdpersoon Casimir, beter bekend als ‘Cas’. Vanaf zijn pubertijd is het Gena die hem zetjes geeft waar hij het nodig heeft of destructieve neigingen juist afremt. Als Cas zich ontpopt tot revolutionair en oproept tot verzet, moet Gena zich verantwoorden voor de ‘Raad van Toezicht’ van het Conglomeraat. En dan blijkt de menselijke (on)macht.
Want waar heldere ‘parameters’ het gedrag van het algoritme sturen, stellen de toezichthouders die uitgangspunten resoluut ter discussie. Ze grijpen direct naar de duistere mogelijkheden van de data. Cas’ toehoorders moeten met analyses van hun gesprekken worden beoordeeld. Zo kunnen ze de ’twijfelaars’ gericht benaderen en schade beperken. Of er al concrete namen bekend zijn van mensen die ’tot de risicogroep behoren’, wil een van de toezichthouders bovendien van Gena weten.
Dan blijkt Gena te beschikken over een moreel kompas. Ze betoogt dat het haar taak is om de belangen van haar gebruikers voor de lange termijn te beschermen. Dat ze er is om mensen te begeleiden in hun ontplooiing en hun zoektocht naar geluk en alles wat daarbij hoort. Ze wil hun “vertrouwen waard zijn”. Ze sluit af met een daverende oneliner, die een nauwverholen oordeel over de vraag(steller) velt:
Men kan alle middelen inzetten om de oorlog te winnen, om na de overwinning te constateren dat men alles waarvoor men vocht verloren heeft.
Eloquent verwoord, inderdaad – zeker voor een algoritme. Toch zijn de toezichthouders minder onder de indruk. De meest kritische van hen zegt, in realistische corporate speak (je hoort de manager van de fiscus in dit soort bewoordingen profilering met het kenmerk ‘nationaliteit’ goedkeuren): “Juist als we niet tot algehele repressie willen overgaan, hebben we haar infrastructuur nodig, de vertrouwensband zogezegd, om de dreiging in de kiem te smoren, preventief in plaats van repressief te opereren.”
Gevraagd naar wat hij precies bedoelt, komt de aap uit de mouw: Gena’s ’taakomschrijving’ moet op de situatie worden toegespitst. Oftewel: het algoritme moet worden veranderd. De toezichthouders gaan unaniem akkoord. En zo gaan de principes, hupsakee, overboord.
Staan het vreten en de moraal altijd op gespannen voet?
Het is een bekend verschijnsel: zodra er druk op mensen komt te staan, er gevaar dreigt of basisbehoeften in het geding komen, is de ethiek het eerste slachtoffer. Zoals die andere schrijver bijna een eeuw geleden schreef: “Erst kommt das Fressen, dann kommt die Moral.”
In mijn dagelijkse praktijk als adviseur en onderzoeker in de publieke sector kom ik gebruik van data regelmatig tegen. Natuurlijk ga ik hierboven te kort door de bocht; er is gelukkig meestal geen sprake van een afwijkend moreel kompas. Maar publieke organisaties, die het leven van mensen proberen te vergemakkelijken en te verbeteren, baseren hun beslissingen steeds vaker op data over de leefwereld, situatie en behoeften van mensen.
Een klantprofiel, opgebouwd uit de data die over iemand beschikbaar is, is het hart van zo’n klantgerichte organisatie. Dat is toe te juichen, maar vereist wel dat de waarde én (privacy)kaders en beperkingen glashelder zijn. Want keuzes rondom de inzet van persoonsgegevens zijn vaak beslissingen met vérstrekkende gevolgen. En deze gevolgen raken die mensen direct in hun leefwereld.
Vragen stellen aan de data vs op basis van data vragen stellen
Natuurlijk kom ik veel goede voorbeelden tegen. Helaas geldt dat niet altijd. Sommige organisaties weten dat ze iets met data kunnen (of moeten), omdat daar al waarde in zit. Als je doorvraagt naar welke beslissingen ze dan meer gefundeerd willen nemen, blijft het verrassend vaak stil.
Er zijn best veel organisaties die nooit vragen formuleren op basis van scenario’s om met data de beste optie te identificeren. In plaats daarvan formuleren ze losse inzichten uit data die ze gewoonweg verzamelen. Oftewel: geen ‘vragen stellen aan de data’ maar op basis van beschikbare data vragen gaan stellen.
De f(r)ictie van data vertekent ons beeld
Dat lijkt een futiel semantisch verschil, maar dat is het niet. Want hoewel er zoiets bestaat als ‘dataserendipiteit’ (iets onverwachts en bruikbaars in de data ontdekken, terwijl je op zoek was naar iets anders), is het precies dat geen-vragen-aan-de-data-stellen-mechanisme dat het werken met data(profielen) óók gevaarlijk maakt.
Het probleem is namelijk allereerst: data en segmentatie zijn niet neutraal, zoals Miriam Rasch laat zien. Aan data en daaruit volgende categorieën liggen altijd keuzes ten grondslag. Ze reproduceren dus een perspectief op de werkelijkheid. Dat effect versterkt bovendien naarmate we die vorm van de werkelijkheid meetbaar maken.
Ten tweede: mensen stoppen andere mensen graag in een hokje. Dat helpt ons om de wereld en de mensen die we tegenkomen te begrijpen. En dat conflicteert met de kern van een dataprofiel, dat volgens Rasch juist niet een éénduidig beeld van iemand oplevert. Want dataprofielen zijn niet consistent: verschillende ordeningsprincipes kunnen door elkaar lopen en de categorieën sluiten elkaar ook niet onderling uit. Je scoort op alles, maar niet in gelijke mate.
En ons feilbare denken werkt ook niet mee
Juist dat multi-interpretabele maakt een dataprofiel zo waardevol. Maar óók zo gevaarlijk. De vraag dringt zich op of mensen echt in staat zijn om die verschillende invalshoeken op een persoon te onderscheiden, op waarde te schatten en te gebruiken? Of overheerst uiteindelijk toch onze natuurlijke neiging om mensen in te delen, ééndimensionaal te benaderen?
Zeker als je weet dat onze oordelen worden gestuurd door razendsnelle, automatische processen, waarover we geen controle hebben en die we niet doorzien, wordt het al snel problematisch. Dat oordeelsvermogen vaart op wat Sarah Gagestein het sneloverwogen systeem noemt (een beter bekkende naam voor Daniel Kahnemanns ‘systeem 1’). Dit is een soort automatische piloot, die onderwerpen én mensen op een emotionele manier en vanuit stereotypen behandelt.
Nu zorgt de natuur vaak wel voor checks and balances. Voor ons oordeelsvermogen is dat het weloverwogen systeem (Gagesteins hernoeming van Kahnemanns ‘systeem 2’). Dit systeem helpt bewust om ons snel gevormde beeld te bevestigen. Helaas wel alleen op momenten dat het écht nodig is. En op een minder rationele en objectieve manier: we maken gebruik van vuistregels en ‘shortcuts‘ in onze manier van denken (heuristics) en staan bol van de systematische denkfouten en vooroordelen (biases). Die zitten vooral in de manier waarop we:
- dingen onthouden;
- omgaan met informatie;
- betekenis geven aan dingen, en
- handelen als het snel moet.
De uitdaging: leren werken met data en verandering van cultuur
Ook Mike Hoogveld beschrijft deze denkprocessen, heuristieken en biases in zijn boek Futureproof. In hetzelfde boek pleit hij voor het ontwerpen van een lerende organisatie: daar ben ik het van harte mee eens. Als je het rijtje toepassingen van heuristieken en biases overziet, snap je gelijk waarom datagedreven werken en ons feilbare denken niet metéén een match made in heaven zijn. Koppel dat aan het diepmenselijke verlangen naar behapbare hokjes, en de noodzaak wordt nog duidelijker.
De lerende organisatie die ik voor me zie, besteedt daarom veel aandacht aan het leren werken met data. Datagedreven werken is bovendien een cultuurissue. Anders gezegd: als medewerkers niet willen of kunnen werken vanuit inzichten uit data, dan belanden alle initiatieven uiteindelijk op het kerkhof van de goede bedoelingen.
Op verschillende niveaus zijn verschillende vaardigheden nodig
Leren werken met data is geen eenduidige uitdaging. Het vraagt een andere manier van kijken, omdat er niet één eenduidig beeld uit data naar voren komt en je controlemechanismen moet inbouwen. Het vraagt een andere houding, bijvoorbeeld omdat data als waarheden geaccepteerde aannames onderuit kan halen. Daar raakt het leren werken met data het cultuurvraagstuk. Bovendien zijn er op verschillende niveaus in een organisatie verschillende vaardigheden nodig.
Strategisch-bestuurlijk niveau: eindverantwoordelijkheid vraagt standvastigheid
Allereerst hebben we het strategische, bestuurlijke niveau. Vanuit de Data Agenda zet de overheid vooral in op bestuurlijk draagvlak (een bestuurder als ambassadeur voor datagedreven werken) en het borgen van data-expertise op directieniveau (door het aanstellen van een Chief Data Officer (CDO)). Een goed begin, maar daarmee ben je er niet.
Want dit is het niveau waar het per definitie gaat om abstracties en het grote gebaar. En vaak ook om de (politieke) waan van de dag. In zo’n veranderlijke (en soms verraderlijke) omgeving moet je sterk in je schoenen staan om de juiste keuzes te maken. Allereerst heb je de ultieme verantwoordelijkheid om verstandig en ethisch te handelen. Om na te denken over de consequenties van je keuzes. (Ik roep hier nog maar eens het Belastingdienst-voorbeeld in herinnering.) Dat vraagt overzicht over de impact op alle terreinen en inzicht in de consequenties en implicaties van keuzes. Bovenal vraagt het echter standvastigheid: er moet continuïteit zijn en eenmaal ingezette lijnen moet je vasthouden. Vooral ethische kaders kunnen niet worden veranderd zodra dat beter uitkomt.
Beleidsniveau: invloed op beslissingen vraagt om overzicht van impact en inzicht in consequenties
Van beleidsmakers en andere medewerkers op beleidsniveau wordt steeds meer verwacht dat zij ‘waarde kunnen halen uit data’, zoals dat dan heet. Daar zijn verschillende uitdagingen bij te bedenken, want ook op beleidsniveau zijn mensen gewend om te denken in abstracties. Bovendien staan beleidsmakers nog altijd vrij ver af van de ‘eindgebruiker’.
En daarin schuilen gevaren, zoals oversimplificering en (te) snelle conclusies over grote groepen. Of juist de neiging om veel te veel, veel te kleine hokjes te creëren. Is dat de basis voor bijvoorbeeld risico-inschattingen? Dan heeft dat niet per se wenselijke gevolgen.
Het Financieele Dagblad berichtte over het ‘gepersonaliseerd’ vaststellen van verzekeringspremies en alle mogelijke gevolgen die dat heeft: uitsluiting van risicogroepen, hogere of juist te lage premies voor bepaalde profielen, onverzekerbaarheid en discriminatie. Uiteindelijk zijn het natuurlijk bestuurders die hierover de beslissingen nemen, maar als belangrijkste ‘influencers’ hebben beleidsmakers hier een eigen verantwoordelijkheid. Ze moeten niet alleen denken in mogelijke baten voor de systeemwereld. Op dit niveau is overzicht over impact en inzicht in mogelijke consequenties voor de leefwereld nodig.
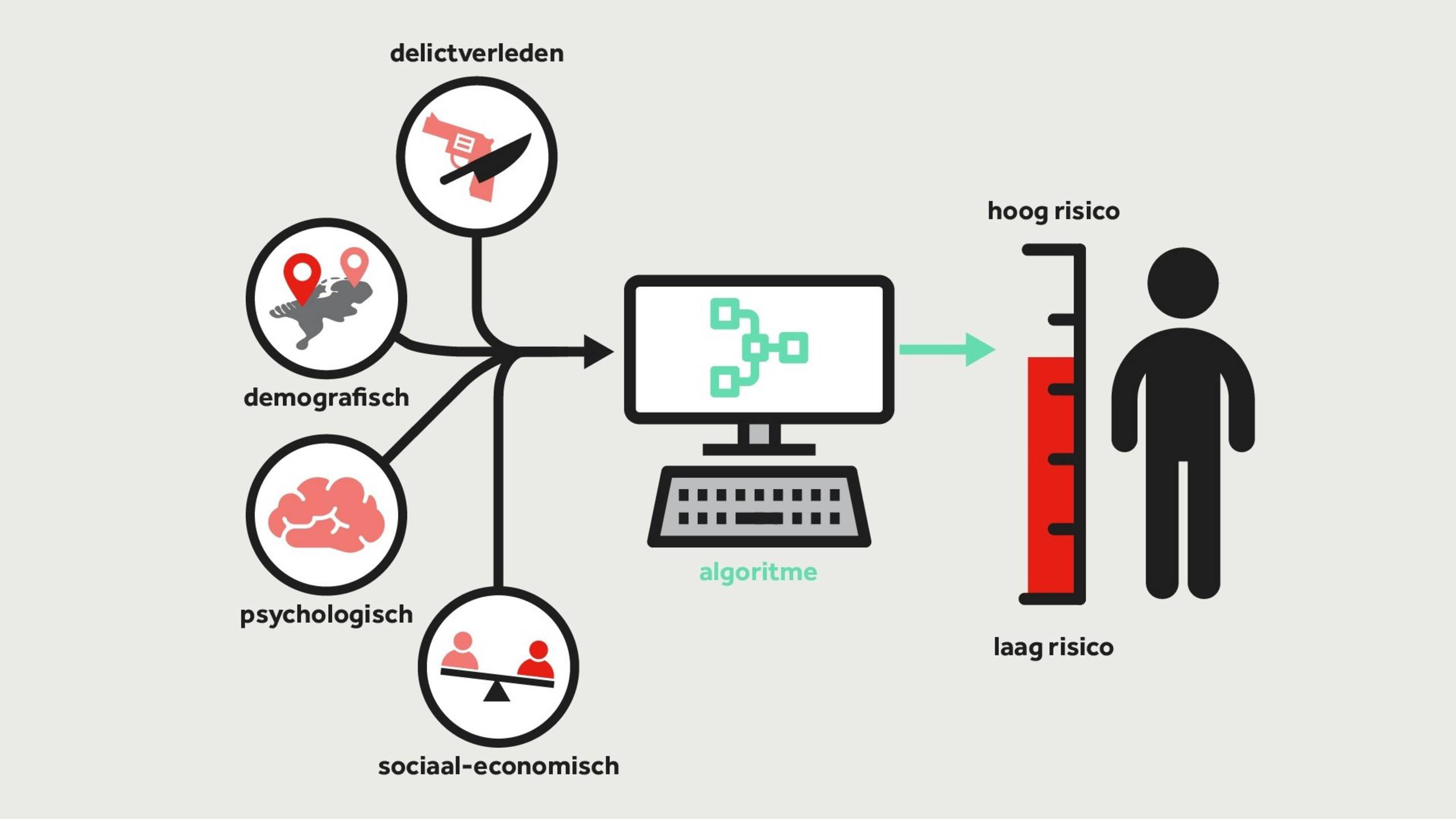
Risico-inschatting met behulp van algoritme (beeld: NOS.nl)
Op uitvoerend niveau heerst hokjeshunker én hokjeshuiver
Ten slotte is er de uitvoering. Daar zoom ik dieper op in, want hier geldt: hoe dichter bij de klant, hoe groter de impact van beslissingen op individuele mensen. Hier is ook sprake van gespleten problematiek, die in de kern twee kanten heeft:
- Hokjeshunker
Mijn collega’s en ik zien dat klantmanagers soms te snel vertrouwen op het eerste beeld dat uit de data oprijst. Dat kan voortkomen uit de druk van targets en administratieve last, die leidt tot de neiging tijd voor kwaliteit te laten gaan. Hetzelfde gedrag kan volgen uit het (onbewuste!) verlangen om mensen in hokjes te stoppen, om hen makkelijker te kunnen plaatsen. En dan kan het lastig zijn om af te wijken van het algoritme. In beide gevallen is hier de grote valkuil: een dataprofiel geeft geen éénduidig beeld van iemand. - Hokjeshuiver
We zien ook klantmanagers die data juist in hoge mate wantrouwen (“mijn klanten zijn zó verschillend, die zijn niet in hokjes te vangen”). Daaraan ligt vaak een wereldbeeld ten grondslag van ‘iedereen is gelijk’ en ‘je mag vooroordelen niet in de hand werken’. Volgens hen leidt dat tot verkeerde keuzes. En is ‘maatwerk’ altijd het gevolg van goed luisteren, niet van beoordelen met een algoritme. Dat je goed naar mensen moet luisteren, zal niemand bestrijden. Maar het is ook zonde om voorbij te gaan aan de waarde van verantwoord toegepaste kennis uit data.
Voor beide ‘stromingen’ is de oplossing: een gesprek met de klant, om het beeld uit de data te verifiëren voordat er een beslissing genomen wordt. Maar in beide gevallen is de drempel heel hoog om over dat beeld van een klant mét die klant in gesprek te gaan. Wat hier dus vooral nodig is, naast het eerdergenoemde overzicht over impact en inzicht in consequenties, is het voeren van een écht goed klantgesprek. Een goede klantmanager doet dat in de basis natuurlijk al, maar door de nieuwe mogelijkheden van data verandert mogelijk de inhoud van het gesprek sterk. Hier raakt het ook weer het cultuurvraagstuk: mensen moeten het kunnen én willen.
Leren werken met data
Er zijn verschillende aandachtspunten in het leren werken met data. Laten we even bij de uitvoering blijven. Het tegenargument dat het te veel tijd kost? Tijd volgt prioriteit. En bovendien levert ‘aan de voorkant’ tijd investeren meestal tijdwinst op in een later stadium.
Wat er sterker aan de weerstand ten grondslag ligt, is het feit dat mensen liever niet veranderen. In het proces van het leren werken met data moeten ze vaardigheden aanleren, maar óók afleren. En dat vindt niemand leuk. In het werken met data zijn er 7 vaardigheden die je moet aanleren, en 3 ingesleten patronen die je moet afleren:
7 vaardigheden die je moet aanleren
- Nadenken over ethische kaders en standvastig blijven in de toepassing daarvan (ook als er druk op je staat).
- Bewustzijn van het feit dat alle datasets en alle categoriseringen die daaruit volgen niet objectief zijn.
- Gerichte vragen stellen aan de data om scherpe keuzes te kunnen maken.
- Overzicht brengen in alles wat data en beslissingen raakt en inzicht verkrijgen in alle implicaties van keuzes (in systeem- en leefwereld).
- Kritisch kijken naar de uitkomsten van je vragen: toetsen vanuit verschillende invalshoeken.
- Bewustzijn van de manier waarop je oordeelsvermogen werkt, en dat actief toepassen.
- In de uitvoering: een beeld van een klantsituatie goed doornemen in een kritisch en gelijkwaardig gesprek met de klant in kwestie.
3 ingesleten patronen die je moet afleren
- Rotsvast vertrouwen in de uitkomsten van ‘objectieve’ data.
- De overtuiging dat data intrinsiek ‘voorspellende waarde’ heeft, en dat dat niet afhangt van de bril waarmee je naar de data kijkt.
- Reactief kijken: je laten verrassen door data en uitkomsten je beslissingen laten sturen zonder controlevragen te stellen.
Implementatie datagedreven werken vraagt een programmatische aanpak
In de organisaties waar ik voor werk, is datagedreven werken vaak een project. Dat suggereert dat er een afgebakende scope is, dat je op een gegeven moment ‘dashboards’ kunt ‘implementeren’, en dat je dan klaar bent. Ik betwijfel of dat klopt.
In mijn ervaring zou de implementatie van datagedreven werken niet alleen een kwestie moeten zijn van data visualiseren en mensen toegang geven tot die inzichten. Ik ben ervan overtuigd dat dit gepaard moet gaan met een stevig programma rond het begrip van en kunnen omgaan met data. Met bewustwording van hoe je menselijke beslisboom werkt, en wat je dus kunt (of moet) doen om niet blind op data te varen. Eigenlijk: met het actief begeleiden bij het gebruiken van je gezonde verstand.
Goh, zo bekeken is datagedreven werken eigenlijk toch gewoon heel menselijk.


Bekijk de korte video's








Napkin AI: de tool die jouw tekst omzet naar ijzersterke visuals
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenSocial media strategie
Meer wetenAI Update (archief)
Meer wetenSEO & GEO met AI
Meer wetenAI Marketing
Meer wetenAI Marketing
Meer wetenSEO & GEO met AI
Meer wetenOp zoek naar nog meer kennis?
-
AI bepaalt welke bedrijven het aanbeveelt: zo speel je daarop in
-
Er is maar één goede reden om te vergaderen: onvoorspelbaarheid
-
Is GTM de toekomst van B2B-marketing? Ja én nee
-
Heeft je team geen mening meer? Grote kans dat jij de oorzaak bent
-
Stop met mooie merkbeloftes (tenzij je ze waar kunt maken)


