
De informatie-explosie: zo overleef je als overheid


De hoeveelheid informatie waar een overheid mee te maken heeft, groeit sterk. Een groot deel van deze informatie komt niet uit de eigen organisatie, maar van buitenaf: burgers, bedrijven, leveranciers, collega-overheden en andere stakeholders zorgen voor een stortvloed aan inkomende informatie waar je als overheid ‘iets’ mee moet. Deze informatie komt ook nog vanuit steeds meer ‘hoeken en gaten’ binnen, want ook het aantal kanalen waarover gecommuniceerd wordt, groeit.
Als overheid wil je deze informatie zo efficiënt mogelijk in goede banen leiden en daarheen brengen waar het benodigd is. Zo kun je waarde leveren aan de maatschappij. Maar begin hier maar eens aan. Dit is – niet heel verrassend – een enorme uitdaging.
Het slechte nieuws: dit artikel geeft je niet alle antwoorden die je nodig hebt, want het is een problematiek die niet in een paar digitale A4’tjes te omvatten is. Het goede nieuws: er zijn zeker een aantal tips die je kunnen helpen om meters te maken. Waarbij je moderne technologie voor je aan het werk zet. Een aantal van deze tips geef ik je in dit artikel.
Een verdieping in de problematiek
Wat is er nu zo complex? Waarom is het zo lastig om controle te krijgen op inkomende informatie? Het is vooral een combinatie van factoren die het probleem complex maken. Ik noem een paar belangrijke.
Groeiende hoeveelheid informatie
De hoeveelheid informatie die op organisaties afkomt, groeit. Dit geldt voor overheden, maar ook voor niet-overheden. Een jaarlijks onderzoek van AIIM, een internationaal onderzoeksbureau op het gebied van informatiemanagement, bevestigt dit. Twee vragen in het onderzoek waren relevant voor deze stelling.
De eerste vraag ging over de hoeveelheid papieren documenten die door processen in de organisatie stroomt. Veel mensen (waaronder ik) zullen aannemen dat deze stroom consistent afneemt, maar dit blijkt een overhaaste conclusie te zijn.
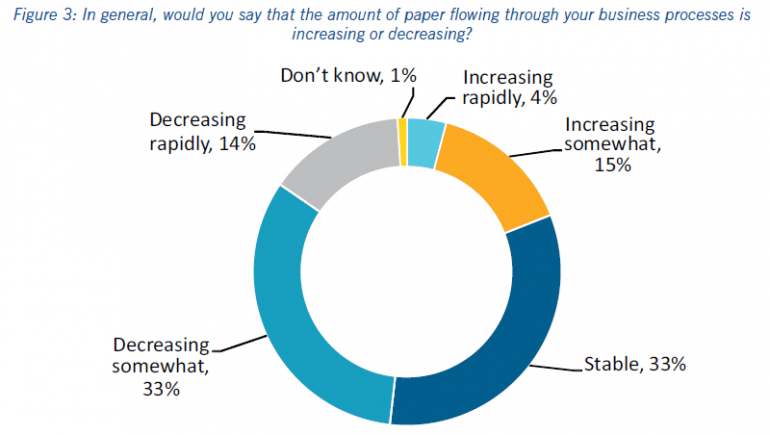
Bron: AIIM 2016
33% van de respondenten antwoordde op deze vraag dat de papieren stroom stabiel is, dus in ieder geval niet afneemt. 15% gaf aan dat de stroom toeneemt en 4% gaf zelfs aan dat deze stroom snel toeneemt. In totaal gaf dus maar liefst 52% van de respondenten aan dat de papieren documentstroom niet afneemt en bij 19% nam deze stroom zelfs toe. Slechts 47% van de respondenten gaf aan dat de papieren stroom afneemt. Minder dan de helft dus. Een (in ieder geval voor mij) verrassende uitkomst.
Dat brengt me op de tweede relevante vraag in het AIIM-onderzoek. Deze vraag ging over de hoeveelheid digitale documenten die in de organisatie binnenkomt. Op deze vraag antwoordde 22% van de respondenten dat deze stroom stabiel is. 47% gaf aan dat deze stroom toeneemt. En 19% gaf aan dat deze stroom snel toeneemt. 66% van de respondenten gaf dus aan dat de inkomende digitale documentstroom toeneemt. Tegenover slechts 10% van de respondenten die aangaf dat deze stroom afneemt.
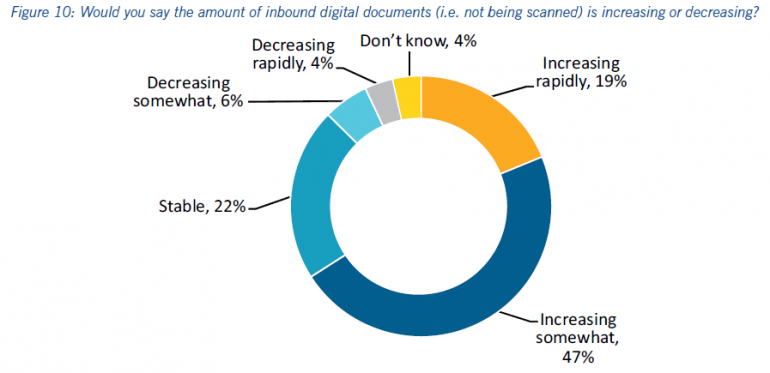
Bron: AIIM 2016
Het aantal kanalen groeit
We communiceren dus (met z’n allen) steeds meer, maar de hoeveelheid kanalen waarmee we dit doen groeit ook. Dit geldt zeker voor overheden: burgers, bedrijven, leveranciers en andere stakeholders communiceren tegenwoordig op tig manieren met gemeenten en andere overheden.
Nog niet eens zo heel lang geleden waren er voor overheden twee of hoogstens drie smaken: de balie, de telefoon en de post. Door de jaren heen zijn hier steeds meer (digitale) kanalen bijgekomen: e-mail, e-formulieren, webportalen, social media, mobiele apps en WhatsApp. Stuk voor stuk kanalen waarmee belangrijke informatie een overheidsorganisatie bereikt.
Ik durf mijn hand ervoor in het vuur te steken dat dit rijtje in de toekomst alleen maar langer wordt. Er komen alleen maar kanalen bij en er valt nagenoeg nooit een (achterhaald) kanaal weg. Zelfs de fax, een hopeloos verouderd stuk technologie, wordt vandaag de dag nog steeds ingezet door organisaties. In sommige branches wordt de fax zelfs nog heel veel gebruikt.
Mix van digitale en niet-digitale informatie
Dat de hoeveelheid informatie groeit, is één ding. Dat de hoeveelheid kanalen waarover deze informatie de organisatie binnenkomt ook groeit, dat is een tweede. Maar wat het extra complex maakt, is dat een deel van deze kanalen niet-digitaal zijn en het andere deel dat wel is.
En dat zal voorlopig voor overheden zo blijven, want ook in het nieuwe regeerakkoord (pdf) staat het volgende:
Mensen die niet elektronisch kunnen communiceren, moeten dat ook op een andere manier kunnen blijven doen. Daarom blijft er een keuzemogelijkheid om per post met de overheid te communiceren.
In veel opzichten zijn er dus twee verschillende werelden. Digitale en niet-digitale informatie moet echter wel bij elkaar gebracht worden. Je hebt een compleet informatiebeeld nodig en de informatie moet dezelfde processen in.
Dat dit een stevige uitdaging kan vormen, blijkt uit onderstaande antwoorden van de AIIM-respondenten. 30% van de respondenten geeft aan dat ze moeite hebben met het bij elkaar brengen van papieren en digitale informatie. Hetzelfde percentage respondenten geeft aan dat ze papieren en digitale informatie helemaal niet bij elkaar brengen en 28% geeft aan dat digitale documenten worden geprint om ze hetzelfde te kunnen verwerken als de papieren documenten. Dat laatste is wat mij betreft de omgekeerde wereld!
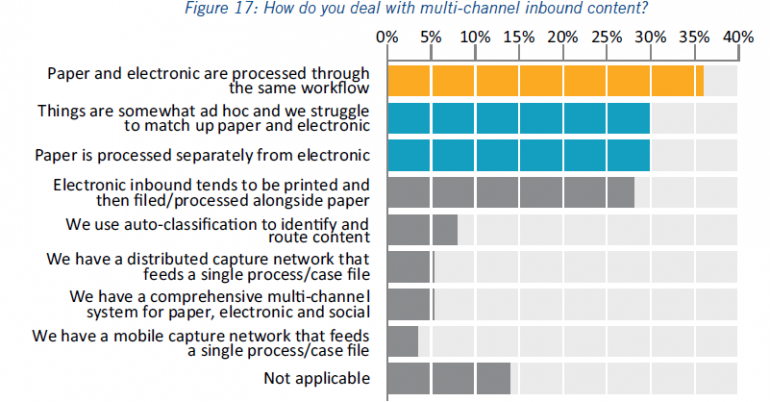
Bron: AIIM 2016
Groot deel van de informatie is ongestructureerd
Als je iets met informatie wil doen, dan helpt het enorm als die informatie gestructureerd is. Een voorbeeld van gestructureerde informatie is de output van een e-formulier. Je weet precies welke informatie waar staat en welk nut die informatie dient. De werkelijkheid is helaas een stuk grilliger: de bulk van de informatie die binnenkomt in een overheidsorganisatie is ongestructureerd. Denk aan e-mails, brieven en socialmedia-berichten. De uitdaging is om ‘chocolade’ te maken van deze informatie en dat is maar al te vaak arbeidsintensief, handmatig werk.
Hier tussenin zweeft semigestructureerde informatie. Een goed voorbeeld hiervan zijn facturen. Je weet dat hier een aantal belangrijke gegevens in staan (zoals een totaalbedrag, btw-bedrag, IBAN), maar deze gegevens staan bij iedere leverancier op een andere plek (uitgezonderd e-facturen).
Op grond van de factoren die ik zojuist genoemd heb, kun je concluderen dat het verkrijgen van de informatie uit de documenten een grote uitdaging is. Zeker als je dit geautomatiseerd wil doen.
Tip 1: Verhuis het digitaliseringsproces naar de voorkant
Ik begin bij de basis: de meeste overheidsorganisaties krijgen nog enorme bulken met papieren documenten binnen. De informatie in deze documenten moeten dezelfde processen in als de informatie van digitale documenten en dat is op zijn zachtst gezegd een uitdaging. Het is belangrijk om de niet-digitale informatie zo snel mogelijk te verenigen met de digitale informatie.
Het digitaliseringsproces bij overheden is vaak op gang gebracht aan de archiefkant van de organisatie. Dit heeft meerdere redenen, compliancy is daar een belangrijke van. Het afleggen van verantwoording op besluitvorming is een stuk eenvoudiger als informatie, die ten grondslag ligt op een besluit, digitaal is geborgd. Om deze reden worden documenten gedigitaliseerd op het moment dat ze gearchiveerd worden.
Het is belangrijk om de niet-digitale informatie zo snel mogelijk te verenigen met de digitale informatie.
Om de vraagstukken van vandaag te kunnen oplossen, is meer nodig dan dat. De informatie die “opgesloten” zit in documenten, is in tal van processen nodig. Dus hoe krijgen we die informatie zo snel mogelijk al die processen in en bij de juiste mensen die het nodig hebben? Dit is alleen mogelijk wanneer documenten zo snel mogelijk worden gedigitaliseerd. Direct wanneer ze de organisatie binnenkomen, niet pas als er gearchiveerd wordt. Het helpt enorm wanneer dit zoveel mogelijk op een centrale plaats gebeurt. Dat brengt me op tip 2.
Tip 2: Pak digitaliseren centraal aan
Iedere overheidsorganisatie is op een bepaald niveau wel bezig met digitaliseren. We komen alle smaken tegen: digitaliseren met of zonder hulp van capture software, digitaliseren met multifunctionals, scanstations, usb-scanners en ga zo maar door.
Voor welke oplossing je ook kiest, overweeg het volgende: onderzoek of je het digitaliseringsproces centraal (of centraler) kunt aanpakken. Hier bedoel ik mee dat dit proces (te) vaak decentraal wordt aangepakt. Dus per afdeling, per administratie, per organisatieonderdeel, etc.
Wat is op de lange termijn de beste oplossing?
Het is natuurlijk niet vreemd dat dit gebeurt. Er zijn minder mensen en disciplines bij betrokken, dus is het makkelijker te realiseren en sneller geïmplementeerd. Een goed voorbeeld is de postkamer, waar (algemene) post de organisatie binnenkomt en de financiële afdeling die papieren facturen ontvangt op een andere postbus. In veel organisaties worden de facturen op de financiële afdeling ontvangen en gedigitaliseerd. Maar is dit op lange termijn de beste oplossing? Alleen als de totale hoeveelheid te digitaliseren documenten laag is, dan is dit het geval. In alle andere gevallen is het veel efficiënter om alle fysieke documenten (inclusief de facturen) op één plek binnen te laten komen en het daar direct te digitaliseren.
Dit betekent overigens niet dat je niet decentraal kunt beginnen. Vaak is er eerst een succesverhaal nodig om draagvlak te creëren voor een organisatiebreed traject. Digitaliseringsinitiatieven kunnen dus goed beginnen op één afdeling of organisatieonderdeel. Mijn boodschap is vooral: laat het daar niet eindigen!

Tip 3: Verdiep je in de mogelijkheden van herkenningstechnologie
De eerste twee tips waren vooral interessant voor organisaties die te maken hebben met grote hoeveelheden binnenkomende papieren documenten. Vanaf tip 3 verandert dit. Tip 3, 4 en 5 zijn namelijk even interessant voor documenten die digitaal binnenkomen als voor documenten die op papier binnenkomen en gedigitaliseerd worden.
Zowel voor gedigitaliseerde documenten als voor digitale documenten geldt dat het van cruciaal belang is om relevante informatie uit de documenten te halen. De informatie die in de documenten staat, is tenslotte nodig om waarde te kunnen leveren voor de organisatie. Nu kan die informatie er handmatig uitgehaald worden, maar dat is pijnlijk arbeidsintensief. Dit wil je automatiseren en dat doe je met herkenningstechnologie.
Herkennen van tekst
Verschillende zaken op een document kunnen herkend worden. Ik begin bij de eenvoudigste die bijna iedereen kent: ‘OCR’ (Optical character recognition), het herkennen van tekst op ingescande documenten. Dit is voor ingescande documenten de basis voor meer geavanceerde vormen van herkenning die ik hieronder bespreek.
Herkennen van documentsoort
Het automatisch laten herkennen van het type en/of soort document heet ‘classificatie’. Het herkennen van een documentsoort kan heel handig zijn, zeker als documenten in grote hoeveelheden binnenkomen. De verschillende documenten kunnen dan gesorteerd worden op basis van de documentsoort. Zo gaan digitale facturen bijvoorbeeld automatisch het factuurproces in, ook al worden ze tegelijk gedigitaliseerd met tal van andere soorten documenten. Maar met deze vorm van herkenning kun je nog een stap verder gaan. Zo is het ook mogelijk om facturen van verschillende administraties automatisch te herkennen en in verschillende processen terecht te laten komen.
Een ander voorbeeld waar classificatie veel werk bespaart, is bij het herkennen van documentsoorten in personeelsdossiers. Een gemiddeld personeelsdossier bevat tussen de 40 en 50 verschillende soorten documenten. Deze variëren van gestructureerde documenten zoals arbeidscontacten, beoordelingsformulieren, UWV-documenten, salarisoverzichten tot ongestructureerde documenten, zoals correspondentie, e-mails en gespreksnotities. Met gedegen classificatie herken je vrijwel volledig automatisch alle verschillende personeelsdocumenten.
Herkennen van informatie
Als je bovenstaande herkenning hebt toegepast op een document, dan ben je al een heel eind. De afbeelding is omgezet naar tekst (in het geval van een gescand document) en de documentsoort is herkend. Nu wordt het tijd om de informatie in het document te herkennen en eruit te trekken, zodat het gebruikt kan worden in een digitaal proces. Dit doen we met een andere vorm van herkenning, genaamd ‘extractie’.
Het meest eenvoudige en meest voorkomende voorbeeld is een factuur. In iedere factuur staat informatie die nodig is om de factuur te kunnen verwerken: een IBAN, een totaalbedrag, een btw-bedrag, etc. Met extractie trek je deze gegevens uit de factuur, zodat het financieel systeem de factuur kan verwerken. Er zijn ook veel andere toepassingen voor data-extractie. Bijvoorbeeld formulieren, enquêtes, etc. Ook uit een barcode kun je informatie onttrekken, denk aan metadata, zoals een personeelsnummer of een klantnummer.
Extra tip bij herkenning
Een extra tip die ik je wil meegeven bij het onderwerp ‘herkenning’, is dat dit valt of staat met de kwaliteit van de herkenning. Dat wil zeggen: welk percentage van de informatie kan automatisch worden herkend? En wat is de foutmarge van de herkenning? Als informatie niet automatisch kan worden herkend, valt dit in een “uitvalbak” en moet het worden aangevuld. Handmatig werk dus. Dit geldt nog meer voor informatie die niet juist is herkend. In zo’n geval moet verkeerd herkende informatie worden gecorrigeerd. Een 100% herkenning van ieder document is een utopie, maar met de juiste technologie kun je dicht in de buurt komen.
Er zijn verschillende “trucs” om dit proces zo nauwkeurig mogelijk te maken. Zo kun je werken met een dubbele vorm van herkenning: wanneer de eerste vorm van herkenning faalt, wordt er overgegaan naar een tweede. Of je kunt informatie valideren. Zo kun je bijvoorbeeld checken of een IBAN bestaat, een postcode of telefoonnummer de juiste opmaak heeft, etc.
Tip 4: Verbind informatie met processen
Deze tip heb ik al een beetje opgewarmd bij tip 3, want als het type document en de informatie in het document is herkend, dan ben je helemaal klaar om deze informatie automatisch in een digitaal proces te zetten.
In het voorbeeld van een factuur, heb je alle informatie om de factuur automatisch:
- door te zetten naar de personen die de factuur moeten accorderen.
- na akkoord de herkende gegevens door te zetten naar het financieel systeem voor betaling.
Het factuurproces is natuurlijk maar één voorbeeld. Er zijn heel veel processen te bedenken waarbij de informatie binnen documenten nodig is in een proces. Denk aan klachten, aanvragen, wijzigingen, HR-documenten, etc. Zorg er daarom voor dat capture-processen voor papieren én digitale documenten verbonden worden met (digitale) bedrijfsprocessen. Een goed voorbeeld is het koppelen van digitale informatie met bestaande workflows in een ECM- of EIM-platform.
Vind je het lastig om te bepalen waar je moet beginnen? Evalueer welke (bedrijfskritische) processen vertraging oplopen en waarom dit gebeurt. Geheid dat er verschillende processen zijn die baat hebben bij het automatisch matchen van informatie en proces.
 Tip 5: Zorg dat processen van a tot z digitaal zijn
Tip 5: Zorg dat processen van a tot z digitaal zijn
We hebben met bovenstaande stappen een situatie gecreëerd waarbij informatie die de organisatie binnenkomt:
- efficiënt wordt gedigitaliseerd, mocht het op papier de organisatie binnenkomen.
- herkend wordt, zodat de informatie bruikbaar is.
- verbonden wordt met digitale processen, zodat je de informatie voor je kunt laten werken.
Gevaar
Nu ligt er een gevaar op de loer, dat ervoor kan zorgen dat dit werk allemaal voor niets is geweest. Dit gevaar is: een proces dat niet 100% digitaal is.
Ik chargeer natuurlijk een beetje om een punt te maken, want niet al het werk is dan voor niets geweest. Maar wat ik ermee wil aangeven, is het volgende: hoe klein dit stukje ook is, het kan betekenen dat er – midden in het proces – weer papier en handmatig werk ontstaat. Dat is natuurlijk eeuwig zonde!
Ik illustreer met een voorbeeld wat er kan gebeuren. Ik gebruik hiervoor weer (het inmiddels bekende) factuurproces, omdat dit proces voorkomt in iedere organisatie. Stel, je organisatie komt van ver, maar heeft heel wat in het werk gesteld om facturen te digitaliseren en automatisch te verwerken:
- Facturen die op papier binnenkomen, worden direct bij binnenkomst gedigitaliseerd.
- Gegevens op de facturen worden automatisch herkend.
- Herkende gegevens worden automatisch doorgezet naar het financieel systeem.
- De facturen worden via het systeem naar de personen gestuurd die moeten accorderen, maar hier zit de crux. De facturen kunnen niet via het systeem geaccordeerd worden.
In bovenstaand voorbeeld is een klein gedeelte van het proces niet digitaal. Er is nog steeds een handtekening of paraaf nodig, waardoor iedere factuur geprint en weer gescand moet worden.
Voor sommige lezers klinkt dit wellicht als een rare situatie, maar het komt bij veel organisaties nog voor. Niet alleen in het factuurproces, maar in diverse processen. Zorg er daarom voor dat een digitaal proces ook werkelijk digitaal is. Van a tot z, zodat je ook echt de vruchten kunt plukken van de automatisering.
Hoe gaat jouw organisatie om met inkomende informatie?
Zoals ik in de inleiding al vermeld: met dit artikel had ik niet de pretentie om alle uitdagingen rondom deze problematiek te laten oplossen als sneeuw voor de zon, maar om je een aantal praktische tips te geven voor verbetering.
Ik hoop dat ik je op weg heb geholpen en ben benieuwd hoe jouw organisatie omgaat met het benutten van inkomende informatie.


Bekijk de korte video's








Napkin AI: de tool die jouw tekst omzet naar ijzersterke visuals
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenSocial media strategie
Meer wetenAI Update (archief)
Meer wetenSEO & GEO met AI
Meer wetenAI Marketing
Meer wetenAI Marketing
Meer wetenSEO & GEO met AI
Meer wetenOp zoek naar nog meer kennis?
-
Zo ga je als marketeer aan de slag met Claude Cowork
-
Nederland scoort hoog op digitale overheid, maar hapert waar het telt
-
Zo zorg je dat kijkers niet wegscrollen bij je YouTube Shorts
-
De 7 grootste mythes over presenteren om eindelijk te ontkrachten
-
AI neemt de productie over en juist daarom wint het echte verhaal




