
Zichtbaarheid in AI-chatbots: het werkt anders dan je denkt


AI search domineert de gesprekken. GEO is het nieuwe etiket. Google AI Overviews en AI-chatbots worden op één hoop gegooid, terwijl ze content volgens fundamenteel verschillende regels verwerken en beoordelen. Daardoor vertrekt het advies dat nu circuleert bijna altijd van dezelfde foutieve aanname: dat ‘AI-systemen’ websites benaderen zoals zoekmachines dat doen. Zo blijft onzichtbaar waar het bestaande SEO- en GEO-advies structureel tekortschiet. In dit artikel maak ik dat onderscheid glashelder en ontleed ik de volledige pipeline, van prompt tot antwoord.
Het onderscheid dat niemand maakt
Dat Google AI Overviews en AI-chatbots vaak samen onder de noemer ‘AI’ worden gecategoriseerd is begrijpelijk, maar misleidend. Op het eerste gezicht lijken ze op elkaar: taalmodellen, antwoorden en vergelijkbare interfaces. Maar onder de motorkap volgen ze een andere systeemlogica. Ik benoem er hieronder 5.
1. AI Overviews: search-first
Google AI Overviews blijft in de kern een zoekmachine. De selectie van bronnen volgt niet één-op-één de klassieke ranking, maar gebruikt die wel als belangrijke signalen. Ook lager gerankte pagina’s uit de zoekindex kunnen worden meegenomen, zoals analyses van Search Engine Land laten zien.
Het antwoord is het eindpunt van een klassiek zoekproces: crawlen, indexeren en ranken. AI voegt daar een generatieve synthese bovenop, maar Google Search bepaalt welke bronnen in aanmerking komen.
SEO blijft hier een selectiemechanisme. Niet als einddoel, maar als voorwaarde om in aanmerking te komen voor opname in AI Overviews.
2. AI-chatbots: standaard zonder zoekmodus
AI-chatbots zoals ChatGPT en Claude vertrekken zonder geactiveerde zoekmodus vanuit een compleet andere uitgangspositie. Het zijn geen zoekmachines met een AI-laag, maar antwoordmachines die werken vanuit hun interne modelkennis. Standaard wordt er niet gezocht.
Dat interne geheugen is gevormd tijdens training op grote hoeveelheden tekst, samengevat tot statistische patronen en gecomprimeerde representaties. Geen live kennis, geen doorzoekbare database.
Een groot deel van dagelijkse chatbot-interacties speelt zich af in deze gesloten kennisruimte. Voor dit type antwoorden heeft on-page SEO nauwelijks directe impact. Wat hier telt, is of een merk, concept of expertise voldoende aanwezig en herkenbaar is in de trainingsdata, via betrouwbare bronnen en consistente entiteiten.
3. AI-chatbots met zoekmodus
Een van de hardnekkigste misverstanden is dat AI-chatbots googelen zoals wij dat doen. Die aanname veroorzaakt veel verwarring rond zichtbaarheid en optimalisatie. Pas wanneer de interne kennis tekortschiet, activeert een chatbot selectief externe bronnen. Dat gebeurt typisch bij recente gegevens, sterk variabele data zoals prijzen of beschikbaarheid, of bij zeer specifieke en lokale vragen.
ChatGPT Search en Claude activeren in dat geval web retrieval via vooraf gedefinieerde search-API’s en andere toegestane kennisbronnen. Dit is geen vrije toegang tot het hele web en volgt niet de klassieke zoekmachine-logica.
Verschillende soorten kennisbronnen worden dan benaderd:
- Web search API’s (via vooraf gedefinieerde third-party search providers, zoals Bing in bepaalde configuraties)
- Real-time crawling via eigen crawlers
- Gelicenseerde datasets (OpenAI’s deals met Reddit en Stack Overflow)
- Gespecialiseerde tools (shopping-API’s, weerdata-API’s, locatiedatabanken)
- Interne documenten (wanneer expliciet gekoppeld of geüpload)
In deze configuratie beslist het systeem eerst dat zoeken nodig is, haalt het vervolgens relevante informatie op en selecteert het daarna welke fragmenten bruikbaar zijn voor het antwoord. Dat proces staat bekend als Retrieval Augmented Generation (RAG).
SEO speelt hier hoogstens een indirecte rol: niet als rankingmechanisme, maar als toegang tot extractie binnen een vooraf afgebakende kennisruimte. De centrale vraag verschuift van ‘word ik gevonden?’ naar ‘blijft mijn content overeind nadat ze door extractie en selectie is gegaan?’
4. ChatGPT-shopping is geen zoeken
Wanneer ChatGPT producten toont, doorzoekt het geen webshops zoals een gebruiker dat zou doen. Er wordt een gespecialiseerde shopping-tool geactiveerd die productdata ophaalt via gestructureerde productfeeds en API’s van e-commerceplatforms. Zichtbaarheid hangt hier af van datakwaliteit, structured data, feeds en partnerships. Het model leest geen productpagina’s, maar verwerkt productattributen.
5. Lokale vragen: geen Maps, wel databanken
Bij lokale vragen fungeert ChatGPT niet als kaart- of navigatiesysteem zoals Google Maps. Het put uit locatiedatabanken, bedrijfsregisters en reviewdatasets. Vaak met beperkte actualiteit en geografische dekking. Dit verklaart waarom lokale antwoorden soms onvolledig of incorrect zijn. Dit is geen zoekmachineprobleem, maar een dataprobleem.
Zichtbaarheid in AI-chatbots is geen optimalisatievraag, maar een herkenningsvraag.
De extractor-pipeline: 8 stappen van prompt tot antwoord
Deze pipeline beschrijft hoe AI-chatbots met geactiveerde zoekmodus werken. Deze is niet van toepassing op Google AI Overviews, dat vertrekt vanuit een klassieke zoekindex en rankinglaag. De termen extractor en selector worden hier gebruikt als analytische labels voor functies die in RAG-systemen expliciet aanwezig zijn, maar niet altijd zo benoemd worden in documentatie.
Tussen een prompt en het antwoord zit geen eenvoudig zoekresultaat, maar een extractor- en selector-pipeline. Die bepaalt niet enkel hoe het antwoord klinkt, maar ook wat überhaupt mag meedoen. Wie deze stappen doorziet, begrijpt meteen waarom klassieke SEO-logica hier vaak ophoudt.
Stap 1. Van prompt naar zoekintentie
Wanneer een AI-chatbot externe informatie activeert, wordt de gebruikersvraag vaak intern geherformuleerd naar een zoekgerichte variant. Bij complexe of meerlagige vragen maakt het systeem daar vervolgens meerdere varianten (fan-out queries) van, zodat het verschillende invalshoeken parallel kan aftasten. Dit bepaalt al vroeg welke aspecten van de vraag als relevant worden beschouwd.
Stap 2. Fetch: toegang tot kennisbronnen
Zoekopdrachten worden uitgevoerd binnen vooraf toegestane bronnen: beperkte webzoekfunctie, gelicenseerde datasets, interne documenten of gespecialiseerde bronnen. Dit is het enige moment waar SEO nog indirect meespeelt, als toegangspoort. Niet ranking is doorslaggevend, maar of een merk herkenbaar is als consistente entiteit over meerdere betrouwbare bronnen heen.
Stap 3. Extractor: van webpagina naar leesbare inhoud
Zodra er content is opgehaald, grijpt de extractor in. De pagina wordt teruggebracht tot haar kerninhoud. HTML wordt gestript. Alles wat niet bijdraagt aan betekenis verdwijnt.
Meestal verdwijnen:
- Navigatie en menu’s
- Headers en footers
- Banners, advertenties en pop-ups
- Contextloze blokken
- SEO-elementen zonder inhoudelijke betekenis
Wat doorgaans overblijft:
- Koppen en kernparagrafen
- Tabellen en lijsten
- Betekenisvolle alt-tekst (afbeeldingen)
- Structured data (mits correct en inhoudelijk consistent)
Lay-out en design spelen geen rol meer. Vergelijk het met de leesmodus van je browser: die komt het dichtst in de buurt van hoe een extractor content ziet.
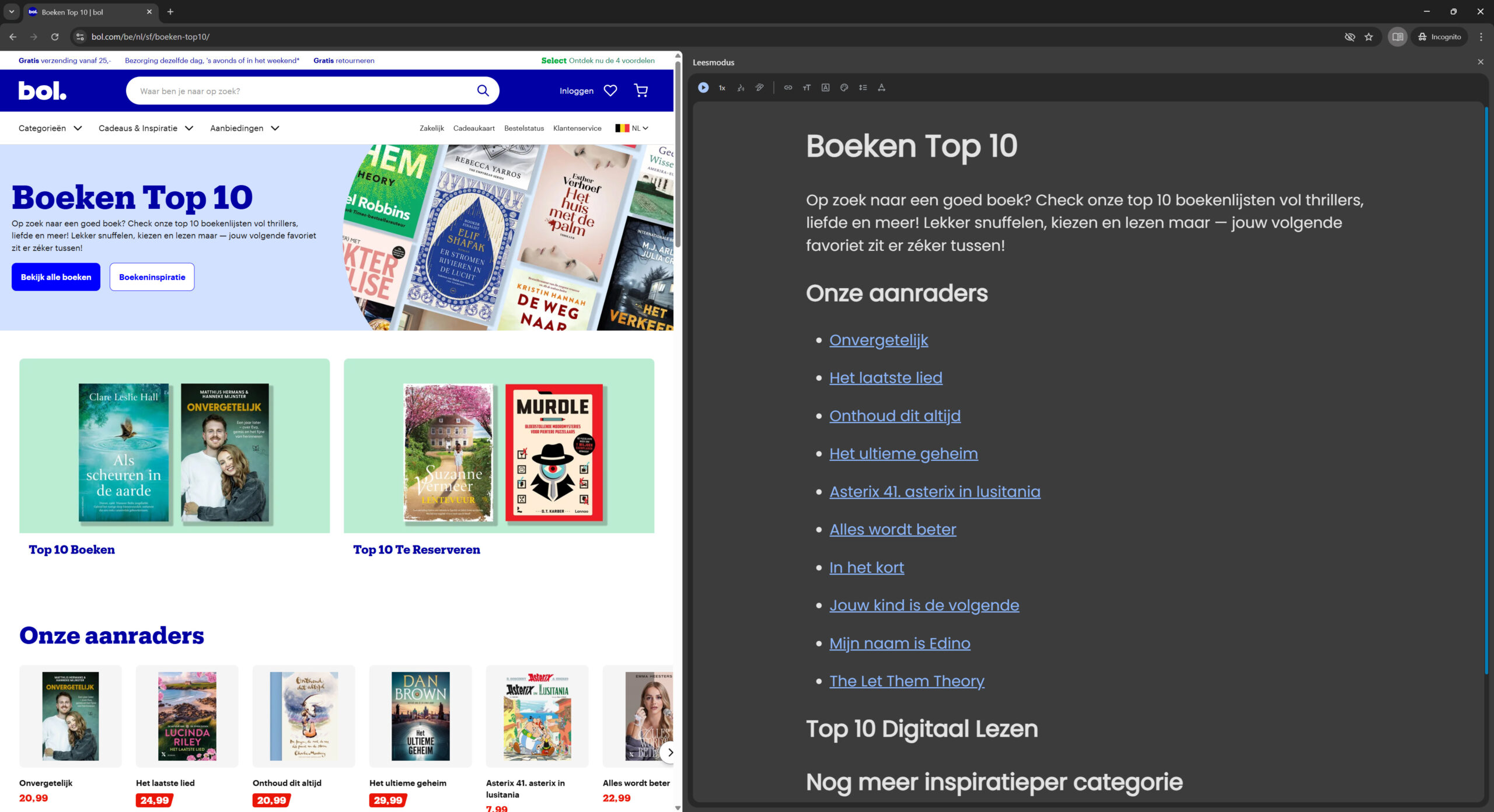 Links: een bol.com-pagina zoals een gebruiker die ziet. Rechts: dezelfde bol.com-pagina in leesmodus.
Links: een bol.com-pagina zoals een gebruiker die ziet. Rechts: dezelfde bol.com-pagina in leesmodus.
Stap 4. Chunking: van inhoud naar betekenisblokken
De vrijgemaakte inhoud wordt opgeknipt in kleinere stukken: chunks. Dit gebeurt niet willekeurig. Het doel is om fragmenten te creëren die zelfstandig betekenisvol zijn. Voor een chatbot is een pagina te groot en te vaag. Elke chunk moet op zichzelf een duidelijk onderwerp hebben en voldoende context bevatten om begrijpelijk te zijn zonder de rest van de pagina. Veel marketingverhalen vallen hier stil: teksten die leunen op opbouw of narratief verliezen hun samenhang zodra ze worden opgeknipt.
Chunking verklaart waarom herhaling, expliciete definities en heldere formuleringen wél werken. Niet omdat ze ‘SEO-vriendelijk’ zijn, maar omdat ze fragment-proof zijn.
Stap 5. Embeddings: taal wordt betekenis
Na het opknippen verdwijnt tekst zoals wij die lezen. Chunks en de oorspronkelijke vraag worden omgezet naar abstracte representaties: embeddings. Numerieke vectoren die vastleggen waar een fragment inhoudelijk over gaat, los van exacte bewoording. De machine vergelijkt geen woorden, maar concepten. Twee teksten kunnen totaal verschillend geformuleerd zijn en toch als sterk verwant worden gezien. Omgekeerd kan een tekst met perfecte keywords volledig irrelevant blijken als de betekenis niet aansluit.
Dit is het punt waar optimalisatietechnieken definitief hun grip verliezen. Het gaat niet meer om termen, maar om inhoudelijke nabijheid. Wat vaag of impliciet is, scoort slechter dan wat expliciet en eenduidig benoemt waar het over gaat.
Stap 6. Selector: bruikbaarheid vóór autoriteit
Op basis van die betekenisvergelijking kiest de selector een beperkt aantal fragmenten die het best passen bij de vraag. Geen ranking zoals bij zoekmachines, maar selectie op bruikbaarheid. Het systeem zoekt niet naar de meest gezaghebbende bron, maar naar fragmenten die inhoudelijk het meest bijdragen aan een correct antwoord.
Hier wordt zichtbaar waarom entiteitsherkenning zo belangrijk is. Fragmenten die consistent gekoppeld zijn aan herkenbare referentiepunten hebben een voordeel: ze zijn betrouwbaarder te plaatsen binnen de kennislaag van het model. Fragmenten zonder context of verankering vallen sneller weg.
Stap 7. Synthese: het antwoord wordt geschreven
Pas nu komt het taalmodel zelf aan zet. Het gebruikt de geselecteerde fragmenten als context en combineert die met de interne kennis om tot een samenhangend antwoord te komen. Wat in eerdere stappen is afgevallen, speelt geen rol meer. Het model kan niet teruggrijpen naar de oorspronkelijke pagina om alsnog extra context op te halen.
De kwaliteit van het antwoord wordt bepaald door de beperkingen van de selectie die eraan voorafgingen. Dit verklaart waarom AI-antwoorden soms overtuigend maar onvolledig zijn: vloeiend geformuleerd, maar begrensd door wat de pipeline heeft doorgelaten.
Stap 8. Weergave en broncontext
In sommige interfaces wordt het antwoord aangevuld met bronverwijzingen. Dat is geen nieuwe retrievalstap, maar een presentatiekeuze. De getoonde bronnen zijn eerder in de pipeline geselecteerd als relevante context.
Bronvermelding betekent dus niet dat de AI ‘achteraf nog eens gekeken heeft’. Wat zichtbaar wordt, is het eindresultaat van filters en selecties die lang vóór de weergave van het antwoord zijn toegepast.
Zonder herkenbare identiteit worden GEO-tactieken op los zand gebouwd en blijft content fragmentarisch.
Hoe word je zichtbaar voor een AI-chatbot?
Na alles wat hierboven is ontleed, is het verleidelijk om meteen naar lijstjes te grijpen: FAQ’s toevoegen, structured data aanscherpen en introductieteksten herschrijven. Dat kan helpen om content leesbaar te maken voor extractors, maar het raakt niet aan het kernprobleem.
De doorslaggevende vraag is of een merk of expertisegebied als herkenbare entiteit bestaat. AI-chatbots werken niet met losse pagina’s, maar met kennisobjecten: stabiele eenheden die betekenis krijgen doordat ze consistent terugkeren in uiteenlopende datasets. Die herkenning ontstaat niet op één pagina, maar over meerdere bronnen heen. Het gaat daarbij niet om marketingkanalen, maar om referentiebronnen zoals Wikipedia en Wikidata, nieuwsmedia, gezaghebbende vakmedia, publieke registers en beleids- en regelgeving.
Zichtbaarheid in AI-chatbots is daarom geen optimalisatievraag, maar een herkenningsvraag. Zonder herkenbare identiteit worden GEO-tactieken op los zand gebouwd en blijft content fragmentarisch. Dat is het verschil tussen bijna meedoen en structureel zichtbaar zijn.
Dit artikel is gecheckt door het SEO-panel.
Bron header-afbeelding: gegenereerd met Midjourney.
Over de auteur