 Employee Experience
Employee Experience Tekstanalyse: een vergelijking tussen mens & computer


Tweets op Twitter, discussies op fora of blogposts op nieuwssites: regelmatig worden we overladen met grote hoeveelheden aan berichten. Wij als mensen kunnen vaak moeiteloos de belangrijkste onderliggende thema’s identificeren bij deze berichten. Maar kan een computer deze berichten ook begrijpen en ontcijferen wat de belangrijkste onderliggende thema’s zijn?
Voorbeeld van data: Mechanical Turk
Wat motiveert mensen om deel te nemen aan taken op Mechanical Turk? Deze vraag speelde door het hoofd van Panos Ipeirotis (associate professor aan de Leonard N. Stern Business School van de New York University). Mechanical Turk is een site waar Turkers (ook wel Workers genoemd) zogenaamde Human Intelligence Tasks (HIT) uitvoeren. Deze taken lopen uiteen van het zoeken naar e-mailadressen tot het beoordelen van de kindvriendelijkheid van restaurants.
Om inzicht te krijgen in de beweegredenen van Turkers plaatste Ipeirotis zijn eigen taak op Mechanical Turk. Bij deze taak konden Turkers 10 dollarcent verdienen door een antwoord te geven op de volgende vragen:
“Why do you complete tasks in Mechanical Turk? Please describe the reasons that motivate you for completing tasks on Amazon Mechanical Turk. Do you do this for the monetary awards? For killing time? Do you consider the tasks fun? What discourages you from completing tasks? What attracts you to participate in a particular task?”
In totaal beantwoordden 148 Turkers bovenstaande vragen. Ipeirotis deelde deze antwoorden met de rest van de wereld via zijn weblog. Als voorbeeld de antwoorden van twee van deze Turkers:

Twee van de 148 antwoorden die de Turkers gaven
De menselijke beoordeling
Om de antwoorden van alle 148 Turkers inzichtelijk te maken riep Ipeirotis de hulp in van beoordelaars. Eerst brachten twee beoordelaars afzonderlijk van elkaar in kaart wat volgens hen de onderliggende thema’s (categorieën) bij de antwoorden waren. De beoordelaars kwamen daarbij uit op negen verschillende categorieën. Vervolgens deelden twee andere beoordelaars alle 148 antwoorden in bij deze negen onderliggende thema’s. Hierbij moet opgemerkt worden dat menigmaal het antwoord van een Turker ondergebracht werd bij meer dan één thema.
De volgende grafiek toont de categorisatie van alle 148 antwoorden. Deze grafiek laat bijvoorbeeld zien dat ongeveer 20% van de ondervraagden in hun antwoord aangaf dat hun motivatie het doden van tijd was (Categorie 1).

Categorieën tekstanalyse
Een extra zakcentje
Deze categorisatie bracht Ipeirotis tot de conclusie dat Turkers deelnemen aan HITs vanwege:
“[…] to get some extra cash and pay for gas, but there is a significant fraction that does it for fun, because they consider Turking interesting, and sometimes even addicting!”
Overigens kan bij de toegepaste categorieën een kanttekening worden geplaatst. Er is namelijk sprake van een zekere overlap. Zo kunnen bijvoorbeeld Income purposes (Categorie 3) en Pocket change or extra cash (Categorie 4) als subcategorieën worden gezien van het meer algemene thema ‘geld verdienen’. Of zulke nuanceringen (subcategorieën) uiteindelijk wel of niet nuttig zijn zal afhangen van de mate van detail dat iemand voor ogen heeft bij het beoordelen van de antwoorden.
Het begrijpen van taal
In het geval van tekst wordt vaak gesproken over ongestructureerde data. Het voorbeeld met Mechanical Turk hierboven laat zien dat je voor het verwerken van dit soort data dikwijls de hulp moet inroepen van beoordelaars. Deze beoordelaars maken de ongestructureerde data inzichtelijk. Zij identificeren namelijk de belangrijkste onderliggende thema’s, en delen dan de teksten in bij deze thema’s.
Maar het zal niet vreemd in de oren klinken dat deze categorisatietaak niet altijd even enerverend is. In het geval van zeer grote aantallen berichten kan dit beoordelaarswerk bijzonder vermoeiend zijn. Denk hierbij aan de grote aantallen tweets bij een ‘trending topic’ en de berichtenuitwisseling via sociale media voorafgaande aan gebeurtenissen zoals Project X in het Groningse Haren. Categorisatie van zulke grote hoeveelheden aan berichten kan interessante informatie opleveren, maar vergt tegelijk een behoorlijke inspanning van de beoordelaars.
Kan een computer de beoordeling overnemen?
Kan een computer daarom niet de taak van de menselijke beoordelaars overnemen? Kan een computer niet zulke teksten lezen en begrijpen, onderliggende thema’s identificeren en ten slotte beoordelen tot welk thema een tekst behoort? Maar dan rijst bij sommigen wellicht de volgende vraag: beschikken wij als mensen niet over een rijke taal met tal van nuances?
Voor het achterhalen van de betekenis van een zin moeten wij als mensen menigmaal ‘tussen de regels door lezen’. En de betekenis van een woord halen wij dikwijls uit rest van een zin (de context). Voor het begrijpen van woorden en zinnen zal een computer over deze menselijke taalvaardigheden moeten beschikken. Alleen dan kan een computer mogelijk de taak van menselijke beoordelaars overnemen en teksten redelijkerwijs onderbrengen bij verschillende thema’s. Een computer kan dan wel goed zijn in rekenen, het begrijpen van taal is toch heel iets anders?

Foto: Quinn Dombrowski
Autofabrikanten, verzekeraars en leveranciers
De afgelopen decennia zijn verschillende modellen ontwikkeld waardoor computers ook taal lijken te begrijpen (voor een overzicht zie Kintsch & Mangalath, 2011). Daarbij zijn veel van deze modellen in staat om de betekenis van woorden te ontrafelen (Landauer & Dumais, 1997). Dit begrijpen van taal door computermodellen schept de mogelijkheid dat computers, net als mensen, grote hoeveelheden aan teksten of berichten op inzichtelijke wijze in beeld kunnen brengen en classificeren.
Deze computermodellen bieden ondersteuning bij onder meer:
- Autofabrikanten komen in een vroeg stadium garantieproblemen op het spoor door reparatierapporten op inhoud te analyseren. Op die manier zijn zij in staat garantiekosten te beperken;
- Verzekeraars brengen schadeoorzaken in kaart door de inhoud van schaderapporten te analyseren. Op basis van de resultaten kunnen adviezen over schadepreventie worden gegeven;
- Leveranciers van consumentenelectronica analyseren aantekeningen van hun medewerkers in callcenters voor een beter klantinzicht.
Een eerste poging van de computer
Geïnspireerd door deze modellen heb ik een eigen computeranalyse ontwikkeld. Met deze analyse heb ik onderzocht of ik de 148 antwoorden van de Turkers op inzichtelijke wijze kon samenvatten. Als een eerste begin heb ik de analyse alle antwoorden laten samenvatten aan de hand van slechts twee thema’s. De analyse geeft de inhoud van deze twee thema’s weer met behulp van zogenaamde themawoorden. De tien belangrijkste themawoorden van de twee thema’s zijn als volgt:

De analyse verduidelijkt de betekenis van deze themawoorden door per thema een aantal representatieve tekstfragmenten te selecteren. Deze tekstfragmenten ontstaan door ieder antwoord van een Turker op te delen in afzonderlijke zinnen. Als het antwoord van een Turker bijvoorbeeld uit vijf zinnen bestaat, dan levert dit vijf afzonderlijke tekstfragmenten op. Wat nu volgt zijn twee representatieve tekstfragmenten voor ieder van de twee thema’s. De oplettende lezer zal opvallen dat menig themawoord (in de vorige tabel) terugkomt in deze tekstfragmenten.

De combinatie van themawoorden en representatieve tekstfragmenten maakt op haar beurt het duiden van de twee thema’s mogelijk. Het eerste thema lijkt betrekking te hebben op ‘de eigenschappen van HITs’. Hieronder valt bijvoorbeeld wat een taak aantrekkelijk óf juist onaantrekkelijk maakt voor een Turker. Het tweede thema lijkt meer te gaan over ‘wat levert deelname aan Mechanical Turk op voor de Turker, of anders gezegd, wat heeft de Turker aan deze deelname?’. Bij het tweede thema gaat het dus meer over de extrinsieke waarde van een taak. Maar halen we nu even de vragen voor de geest die Ipeirotis stelde voor het achterhalen van de motivatie van de Turkers, dan zien we de twee thema’s terugkomen:
“Why do you complete tasks in Mechanical Turk? Please describe the reasons that motivate you for completing tasks on Amazon Mechanical Turk. [Thema 2: do you do this for the monetary awards? For killing time?] [Thema 1: do you consider the tasks fun? What discourages you from completing tasks? What attracts you to participate in a particular task?]”
Wat we hier zien is dat Ipeirotis met zijn specifieke vraagstelling de Turkers gestuurd heeft bij het geven van hun antwoorden. Het interessante aan de analyse is dat deze dit sturen al in een vroeg stadium (met slechts twee thema’s) oppikt en zichtbaar maakt.
Een stap verder
Is deze eerste oplossing met twee thema’s niet erg karig? Dekken deze twee thema’s wel de gehele inhoud van alle 148 antwoorden? Is het niet mogelijk om de inhoud van de Turkers’ antwoorden samen te vatten met meer dan twee thema’s? Mijn analyse geeft aan dat alle 148 antwoorden het beste worden samengevat aan de hand van vier thema’s. Hoe ziet zo’n oplossing met vier thema’s eruit?
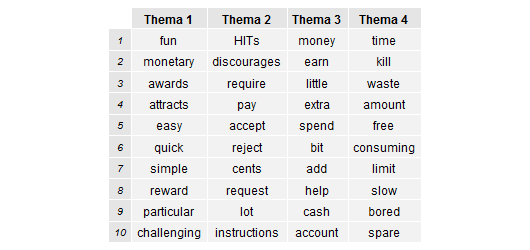
Wederom kunnen de thema’s geduid worden met behulp van representatieve tekstfragmenten. Een mogelijke duiding van ieder thema is hieronder weergegeven, inclusief een representatief tekstfragment. Het percentage bij ieder thema laat zien welk deel van het totaal aantal fragmenten onder een bepaald thema valt. Van alle fragmenten tezamen (totaal 720) valt bijvoorbeeld 31% onder het eerste thema.

Een vergelijking tussen deze vier thema’s en de twee van de eerste oplossing brengt aan het licht hoe de analyse te werk gaat. Wat namelijk opvalt is dat de vier nieuwe thema’s eigenlijk subthema’s zijn. Zij komen voort uit een opsplitsing van de oorspronkelijke twee thema’s uit de eerste oplossing (ter herinnering, dit waren [1] wat zijn de eigenschappen van HITs?, en [2] wat levert deelname aan Mechanical Turk op voor de Turker?). De analyse kan steeds verder gaan met dit opsplitsen van thema’s in subthema’s. Maar hoe ver je wilt gaan met dit herhaaldelijk opsplitsen van thema’s in subthema’s zal uiteindelijk weer afhangen van de mate van detail die iemand voor ogen heeft bij het categoriseren van de antwoorden.
Mens versus computer bij tekstanalyse
Heeft de computeranalyse de teksten begrepen? Dit is een belangrijke vraag en lijkt een voorwaarde te zijn voor het redelijkerwijs kunnen classificeren van teksten. De resultaten hierboven maken duidelijk dat de analyse de samenhang ontdekte tussen bepaalde woorden (zoals tussen money, cash, earn en spend). Deze onderlinge samenhang verleent een zekere betekenis aan woorden (Landauer & Dumais, 1993). Bovendien gebruikt de analyse deze samenhang als bouwstenen voor het opbouwen van de thema’s. Deze thema’s bieden op hun beurt aan ons mensen een context om de woorden in de teksten beter te kunnen plaatsten en te begrijpen.
Zijn er verschillen tussen de resultaten van de menselijke beoordelaars en de computeranalyse? De twee methoden (mens versus computer) lijken soortgelijke thema’s aan te stippen. Zo stippen ze allebei thema’s aan als tijdsbesteding, geldinkomsten en aantrekkelijkheid van de taak (aspecten zoals fun en uitdaging). Door deze overeenkomsten zullen de uiteindelijke conclusies over de motivatie van Turkers niet substantieel verschillen bij de twee methoden. Toch zijn er ook verschillen in de resultaten aan te wijzen. Zo kaart de computeranalyse bijvoorbeeld een thema aan dat verwijst naar de onaantrekkelijkheid van taken. Dit thema zegt iets over wat Turkers demotiveert om deel te nemen aan een taak. De menselijke beoordelaars laten dit thema echter buiten beschouwing.
Maar welke van de twee methoden levert nu de beste resultaten op? Dat eindoordeel laat ik over aan jullie.
Graag wil ik Panos Ipeirotis bedanken voor zijn toestemming van het gebruiken/vermelden van zijn data in deze blog.
Over de auteur



