Zo bouw je een AI-systeem dat je bureau 24/7 laat draaien


Op donderdagmiddag mailt een klant dat het logo op de productverpakking nog niet goed staat. En dat terwijl de research-agent net heeft besloten dat een blog over verpakkingstrends nù af moet, en het publicatiescript wacht op een feedbackronde van een offerte die ik gisteren zelf had moeten beantwoorden. Drie revisierondes lopen tegelijk, vier briefings staan open, en het is half drie. Er is genoeg op te lossen, maar ik weet niet wat eerst moet. Iedere agency-eigenaar herkent dit.
De gangbare oplossing is “AI”. Eén grote assistent die alles kan. Schrijft mijn posts, beantwoordt mijn mail en doet mijn research. Ik heb dat zes maanden geprobeerd. Het werkt twee dagen en valt dan om. Op een rustige dag tikt het door. Op een drukke dag schrijft het de klantmail in de toon van een tweet, en de tweet in de toon van een briefing. Onder druk gaat het mis op exact het moment waarop je het nodig hebt.
Ik heb in de loop van een paar maanden iets gebouwd dat dit oplost. Mijn bureau draait er nu 24/7 op: research, content, communicatie, publicatie. Modelkeuze is verreweg het oninteressantste deel. Het verschil tussen demo en werkend systeem zat in vier architectuurkeuzes, en in zes weken voortdurend dingen breken en repareren.
Ik run sinds zes jaar een branding- en design-bureau voor e-commerce. Tweehonderd-plus projecten, 200+ vijfsterren-reviews. Ik bouw dus geen AI-tools voor de markt — ik bouw ze voor mezelf. Dat verandert je perspectief. Je geeft niet om de demo. Je geeft om wat er gebeurt op donderdagmiddag als een klant kwaad mailt en de AI net heeft besloten dat die blog over verpakking nu af moet.
Waarom één agent je bureau niet runt
De redenen zijn voorspelbaar als je er één keer ingelopen bent.
- Het geheugen raakt vol: een AI-gesprek heeft een eindig werkgeheugen. Als je dezelfde sessie ochtendresearch laat doen, daarna een blog laat schrijven, daarna een klantmail laat draften, dan zit alles door elkaar. De research vervuilt de blog. De klantmail krijgt de toon van een tweet.
- De rollen botsen: research vraagt om breed en snel werken. Schrijven om diep en langzaam. Communicatie om voorzichtig en conservatief. Eén agent met vijf rollen is een persoon met vijf banen. Niemand die ik zou aannemen.
- Er is geen spoor: als alles in dezelfde sessie gebeurt, kun je niet terughalen waarom een bepaald stuk content is geschreven. Bij één klacht of één onverwacht goed presterende post sta je met lege handen.
De oplossing is niet “een betere prompt”. De oplossing is een ander grondplan.
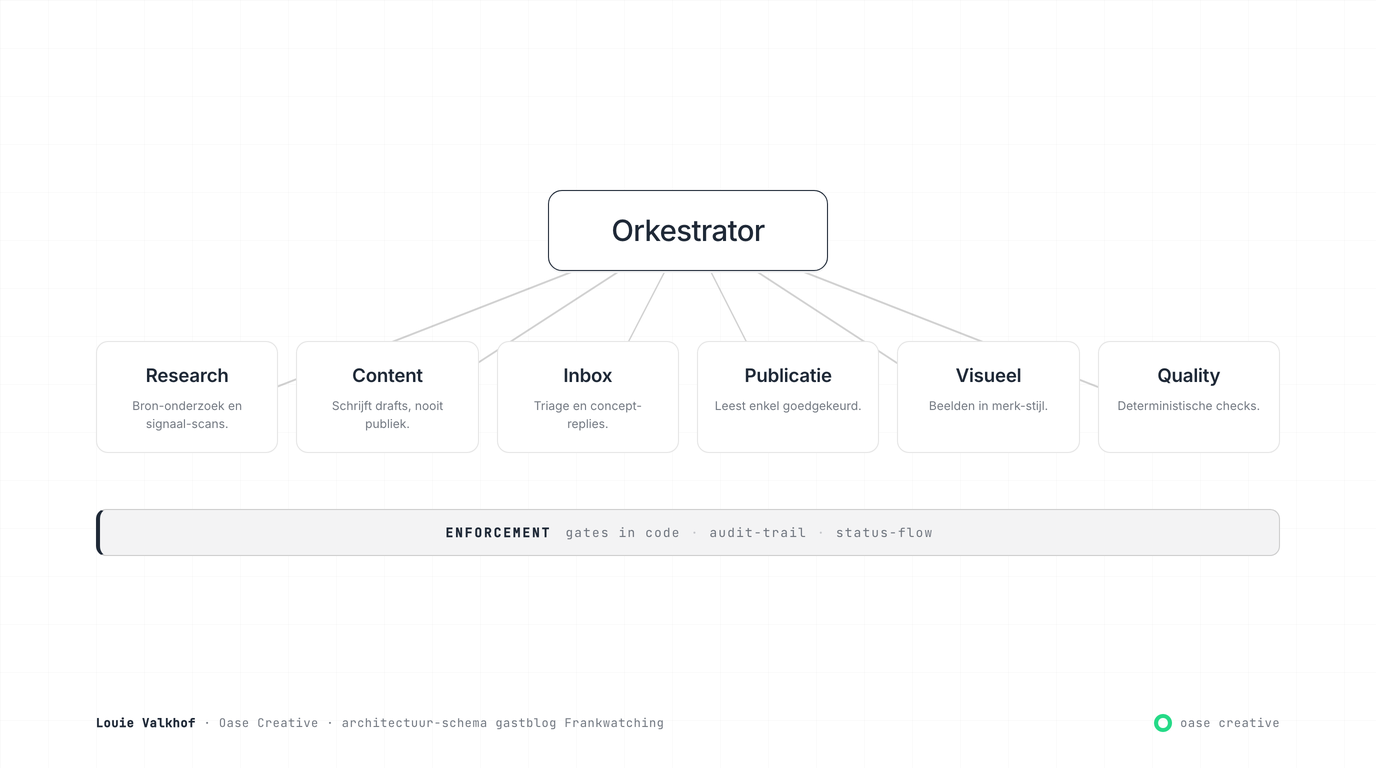
Architectuurkeuze 1: orkestrator plus specialisten
Wat bij mij wel werkt is een patroon dat in software al decennia oud is: één hoofd-agent die niets zelf doet, en een set sub-agents die elk één ding doen. Onderzoek. Schrijven. Communicatie. Publicatie. Beeld. Controle. De hoofd-agent weet niets over hoe research werkt. Hij weet alleen wanneer research moet starten, welk bestand de output bevat, en hoe hij die output doorgeeft aan de schrijver.
Het contract tussen agents staat niet in proza, maar in vier vaste bestanden per agent: wie ben je, hoe doe je je werk, wat heb je geleerd, en waar zet je je werk neer. De hoofd-agent hoeft de inhoud niet te begrijpen. Hij hoeft alleen te weten dat het bestand er is en wat de controle ervan zegt.
Het effect: agents kunnen elkaar niet vervuilen omdat ze elkaar nooit ontmoeten. Elke sub-agent start als verse sessie, doet één ding, en sluit af. Geen kruisbesmetting van toon, geen overvol geheugen, geen rolverwarring.
Bron: Louie Valkhof
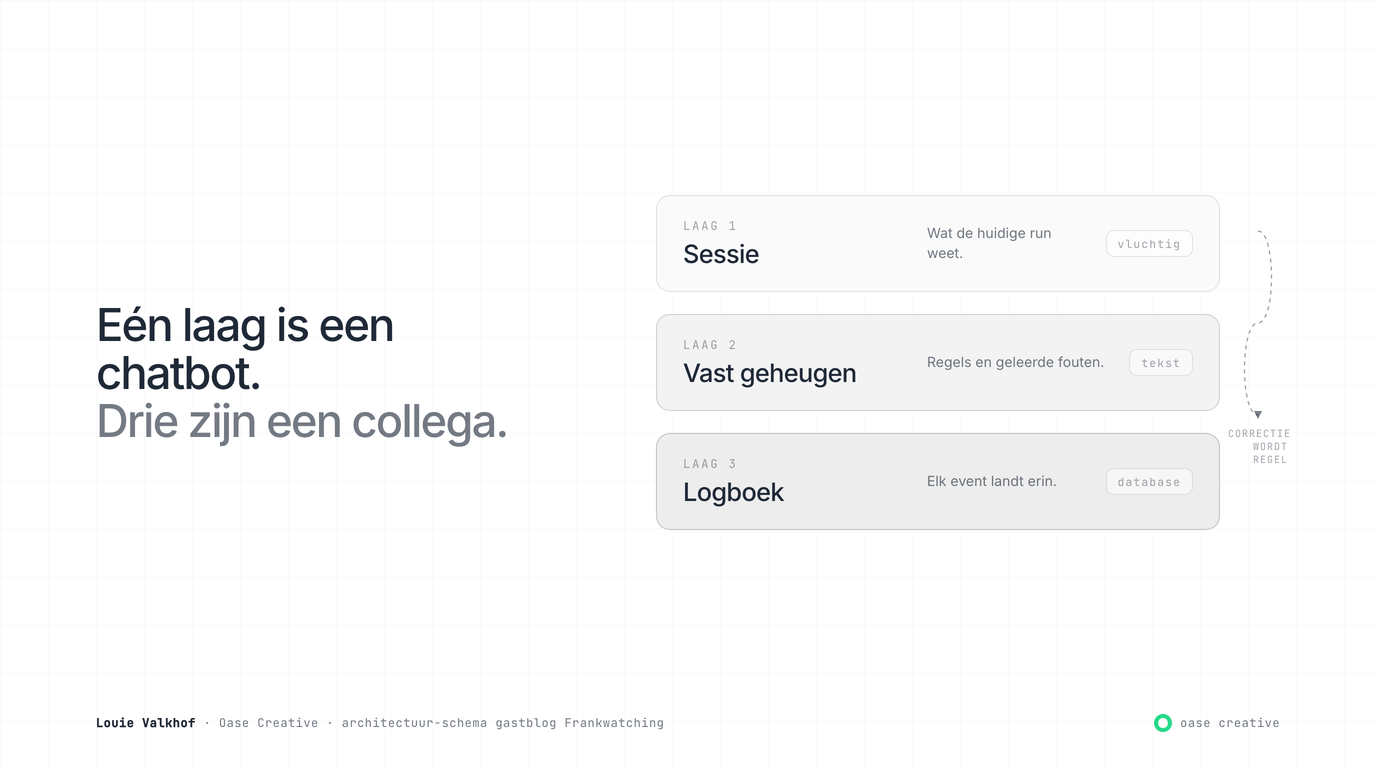
Architectuurkeuze 2: drie geheugenlagen, niet één
Hier loopt iedereen vast. AI-systemen zonder serieus geheugen zijn vermakelijke chatbots. Met geheugen worden ze collega’s.
Drie lagen. Sessie-geheugen is wat de huidige sessie weet, en gaat verloren bij elke restart. Die hoef je niet te bewaren. Vast geheugen is een set tekstbestanden die de identiteit van het systeem vasthouden: wie ben ik, welke regels gelden, welke fouten zijn gemaakt en hoe los ik die op. Logboek is een database. Elk event komt erin: welke beslissing er is genomen, welke conversatie er was, welke content er is gepubliceerd, welke fouten er zijn opgetreden. Bij een crash kan de volgende sessie de laatste acht uur teruglezen en weet binnen één query wat er stond te gebeuren.
De belangrijkste regel is dat correcties niet verloren gaan. Elke keer als ik iets corrigeer (“nee, niet zo, omdat…”), landt die correctie als regel in het vaste geheugen. Niet als incident-melding, maar als regel die volgende sessies zullen lezen. Een systeem dat op die manier leert wordt elke week beter zonder dat je code hoeft te schrijven.
Bron: Louie Valkhof
Architectuurkeuze 3: gates in code, niet in proza
Hier maakte ik in het begin de meeste fouten. Ik schreef regels in de stijl van: “deze agent mag geen klantmails versturen.” Wat denk je dat er gebeurde. Eén keer per twee weken stuurde een agent een klantmail. Niet vaak, maar onvergeeflijk vaak.
Een regel in proza is een hoop. Een regel in het pad is een gate.
Wat bij mij werkt: één centrale lijst waar elk content-item een status heeft. Idee, draft, in-review, goedgekeurd, gepubliceerd. Agents mogen items aanmaken en updaten, maar de stap van in-review naar goedgekeurd mag alleen door mij. Het publicatiescript leest enkel items met status goedgekeurd. Als ik niets goedkeur, gaat er niets de deur uit. Geen prompt die de regel uitlegt. De regel staat in het pad zelf.
Hetzelfde voor klantcommunicatie. De comms-agent draft. De draft komt in mijn inbox. Niets verstuurt totdat ik op verzenden druk. De agent kan onmogelijk de mail rechtstreeks versturen omdat die functie in zijn gereedschapskist niet bestaat. Niet “verboden”, maar fysiek onmogelijk.
Sinds een paar weken werk ik nog een laag dieper: alle risicovolle taken (publicatie, mail, briefing-versturing) lopen via tussenscripts die zelf de status-check, de bron-check en het logboek schrijven vóór de actie plaatsvindt. Geen logregel, geen actie. Sinds die laag heb ik nul publicatie-incidenten gehad. Daarvoor één per twee weken.
Dit klinkt restrictief. Het is bevrijdend. Ik kan een agent grote vrijheid geven binnen de gates, omdat de gates onverbiddelijk zijn. Mijn merk en mijn klantrelatie kunnen niet stuk door een runaway prompt.

Bron: Louie Valkhof
Architectuurkeuze 4: controle die altijd hetzelfde uitkomt
De laatste keuze die het verschil maakte: de controle-laag niet door een AI laten doen. Controle hoort bij scripts die exact dezelfde uitkomst geven bij dezelfde input.
Voorbeeld: een blog moet minstens vijf interne en drie externe links hebben. Een AI-controleur klopt zichzelf op de borst dat hij dat heeft gecheckt en mist toch één keer per zes blogs een link. Een script telt links. Geen pass, geen publish. Einde discussie.
Drie controle-momenten werken bij mij goed: meteen na elke agent-run (links, woordaantal, format), wekelijks dieper (dode links, drift tussen documenten die in sync moeten blijven), en op aanvraag voor specifieke audits. Niets wijzigt zelf output. Alleen flags. De agent of ik fixt. Saai, en saai is wat je wil.
Waarom het systeem eerst brak
De vier architectuurkeuzes hierboven klinken alsof ik dit op papier heb uitgedacht en daarna gebouwd. Dat is niet waar. Het systeem is in zes weken keer op keer gebroken en opnieuw opgebouwd. De huidige vorm is niet ontstaan door inzicht. Hij is ontstaan door uitgleed-momenten waar ik telkens dacht: dit nooit meer.
De content-agent heeft eens een tweet gepost met een feit dat niet in de bron stond — een naam die het systeem erbij verzon. De fout was niet dat de agent de research niet had gelezen. De fout was dat hij feiten mocht opschrijven zonder bron erbij. Pas toen elk feit in publieke content gekoppeld werd aan een specifiek bestand en regelnummer, stopten de hallucinaties.
Een ander moment. De centrale lijst met al mijn content — honderden rijen — werd door een eigen script per ongeluk teruggeschreven als 22 rijen, waarvan de helft stuk. Eén rij had een komma in de inhoud zonder aanhalingstekens; het script las die rij verkeerd en schreef vervolgens een corrupte versie terug. De fix was niet “voorzichtiger zijn met scripts”. De fix was dat elke aanraking aan dat bestand voortaan loopt via één centrale functie die eerst een testrij valideert voordat het bestand wordt overschreven.
Een derde patroon. Geplande agent-runs (research, netwerk-scans) leunden op een truc: de planner stuurde een bericht naar mijn lopende AI-chat met “doe deze taak”. Vijf dagen op rij viel dat geruisloos om — de chat zat in een gesprek met mij, het bericht werd niet als instructie gezien, geen verificatie, geen retry. De briefing van die week miste negen items. De fix was dat geplande taken nu niet meer afhangen van mijn chat-sessie. Ze hebben hun eigen aanjager die los kan lopen, kan falen, en zichzelf meldt.
Drie patronen, niet drie incidents. Achter elk patroon zaten meerdere kleine versies van dezelfde fout. Het systeem werd elke week iets weerbaarder, niet doordat ik beter onthield, maar doordat ik elke fout in het pad codificeerde. Onthouden werkt niet onder druk. Een script wel.
De ene takeaway
Als je dit artikel toch maar voor één regel onthoudt, dan deze: zet onverbiddelijke regels in code, niet in proza. Wat in een prompt staat wordt onder druk overgeslagen. Wat in een pad staat — een script, een statusveld, een tussenstap — wordt nooit overgeslagen. De rest van wat ik heb gebouwd is variatie op die regel.
Hoe begin je zelf
Drie dingen die voor mij het verschil maakten:
- Begin met één rol, niet zes. Kies de meest tijdrovende, niet de leukste. Voor mij was dat content-research. Eén agent, één output, één controle. Werkt dat een week zonder dat je ‘m hoeft bij te sturen, dan voeg je de tweede toe.
- Schrijf je harde regels op vóór je code schrijft. Wat mag dit systeem nooit doen. Wat moet altijd door mij langs. Welke escalatiepatronen gelden. Een agent zonder vooraf vastgelegde regels schrijft die regels zelf, en dat is een slecht idee.
- Gates in code, weerbaarheid in code. Wat onverbiddelijk moet zijn, mag niet als zin in een prompt staan. Status-velden, scripts, paden. En sessies sterven, dus regel een handover-protocol voordat je het nodig hebt, niet erna. Vertrouwen in een 24/7-systeem komt niet van het feit dat het nooit faalt. Het komt van het feit dat herstellen voorspelbaar gaat.
Wat dit nu oplevert
Mijn ochtend ging van twee uur tabbladen managen naar een briefing van vijftien minuten op de loopband. De afgelopen dertig dagen zijn er 44 stukken content gepubliceerd in de juiste toon, op tijd, zonder dat ik er één keer een correctie achteraf heb hoeven sturen. Klantcommunicatie wordt voorgekauwd in plaats van vanuit lege inbox geschreven. Research staat klaar voor ik de zaak open. En ik krijg een melding als er iets niet klopt, niet als alles soepel draait.
Het is geen autonoom bedrijf. Dat is ook nooit het doel geweest. Het is een hulpsysteem met mijn hand op het stuur. Mijn stem, mijn merk, mijn beslissingen blijven van mij. Het systeem doet de uitvoering die niet meer denkwerk verdient dan ze kost.
Veelgestelde vragen
- Op welke schaal werkt dit?
Solo founders en kleine bureaus tot vijf à tien mensen. Het patroon schaalt verder, maar dan groeit de complexiteit en heb je iemand nodig die de orkestratie als product behandelt. Voor de meeste bureaus is het soloversie-model genoeg. - Hoeveel kost dit per maand?
Substantieel minder dan de stack van losse SaaS-tools die het vervangt, en het werkt in de uren dat ik niet werk. Een klein bureau zit tussen de honderd en de driehonderd euro per maand aan kosten plus stroom. De winst zit niet in de tool-kostenbesparing maar in de teruggewonnen ochtend. - Kan ik dit nabouwen zonder te kunnen programmeren?
Niet helemaal. Je hoeft geen software te kunnen bouwen, maar je moet bereid zijn scripts te lezen en kleine stukjes aan te passen. Wie dat niet wil, is beter af met een gehost multi-agent-platform. Wie het wel wil, krijgt een systeem dat van hem is en niet van een leverancier.



Bekijk de korte video's










EU AI Act: wat jij vóór 2 augustus moet regelen
Meer wetenSEO & GEO met AI
Meer wetenCanva met AI
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenDe nieuwe SEO- & GEO-spelregels: scoren in Google én AI-search
Meer wetenAI Update (archief)
Meer wetenSEO-copywriting met AI
Meer wetenSEO & GEO met AI
Meer wetenCommunicatie & AI
Meer wetenContent maken met AI
Meer wetenOp zoek naar nog meer kennis?
-
Heeft je team geen mening meer? Grote kans dat jij de oorzaak bent
-
Stop met mooie merkbeloftes (tenzij je ze waar kunt maken)
-
AI gaat de carrièreladder drastisch veranderen
-
6 AI-prompts die je agile marketingproces direct verbeteren
-
De Wtta treft niet alleen uitzendbureaus: dit moet elke digitale agency weten


