
Zo voorkom je AI-hallucinaties met een slimme controlelaag


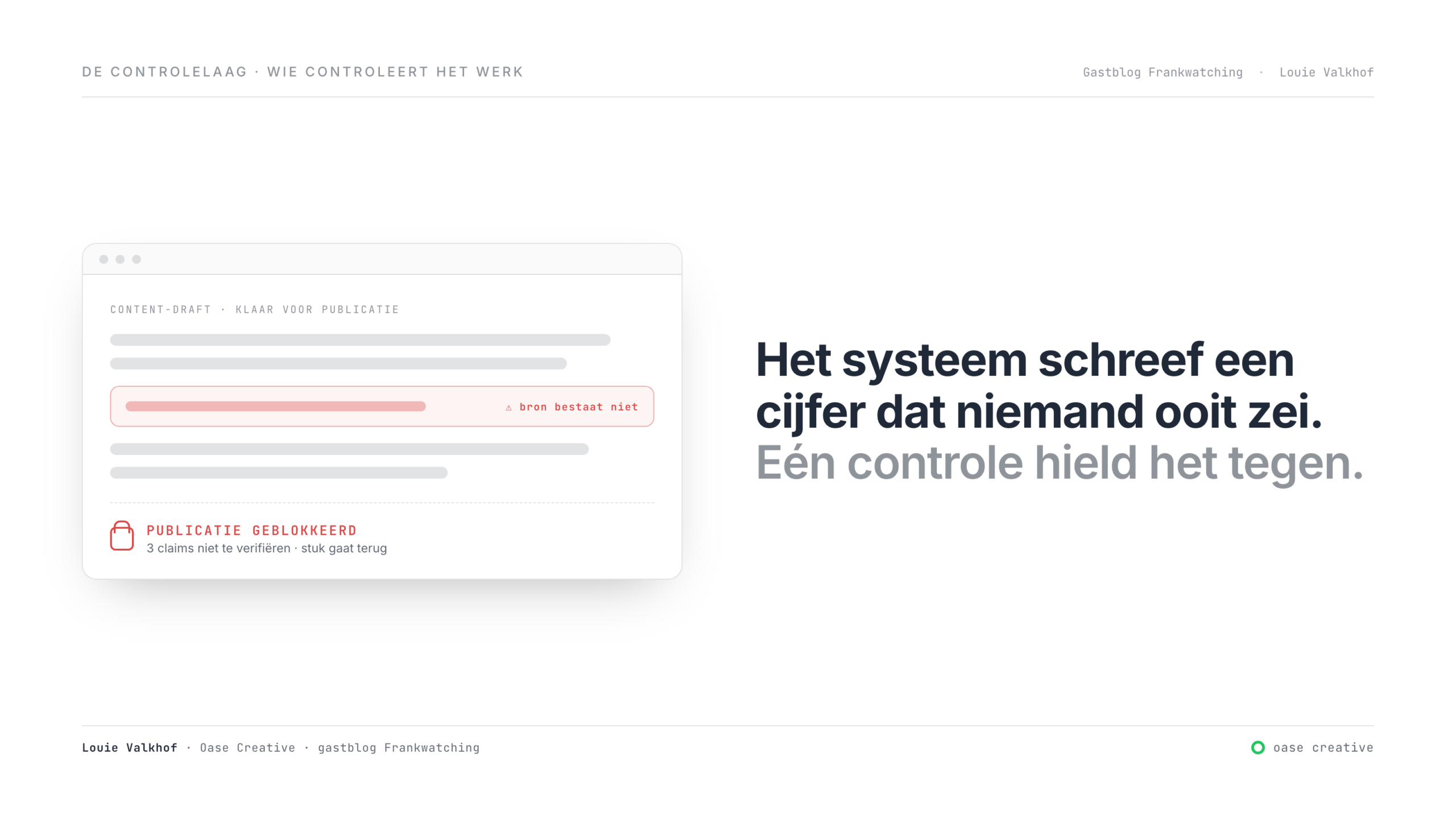
Vorige week stond er een artikel klaar om gepubliceerd te worden met een statistiek van McKinsey erin. Mooi cijfer, precies wat het stuk nodig had. Eén probleem: McKinsey had het nooit gezegd. Het cijfer was verzonnen. Niet door een stagiair, maar door het AI-systeem dat bij mijn bureau de eerste contentdrafts schrijft.
Het had niet één verzinsel. Het had er een handvol. Een nep-bron van JungleScout. Een interne case study met een klant die “17% meer conversie” had gehaald. Een klant en een cijfer die niet bestonden. En één echt getal dat gewoon fout stond: een retailer die volgens de tekst 15% verlies had geleden, terwijl de werkelijkheid een ander percentage was.
Niks daarvan is gepubliceerd. Niet omdat ik het op tijd las, maar omdat er een controle tussen zat die alles tegenhield. En precies daar zit het verhaal van dit stuk.
In mijn vorige artikel hier schreef ik hoe je een AI-systeem bouwt dat je bureau 24/7 laat draaien: de agents, de triggers, de basis. Dat stuk ging over het aanzetten van het werk. Dit stuk gaat een laag dieper, over het deel dat de meeste bureaus overslaan: hoe je zo’n systeem onder controle houdt zodra het écht draait. En over wat dat doet met jouw rol als de mens erboven.
Spoiler: dit verhaal gaat uiteindelijk niet over AI, maar over hoe goed je je eigen proces hebt ingericht.
Het systeem schrijft niet los, het hangt ergens aan vast
Eerst even hoe mijn opzet eruitziet, want zonder dat klopt de rest niet.
Ik run een klein bureau in e-commerce branding. We liepen jaren tegen hetzelfde aan: de bestaande tools pasten niet bij ons werk, dus bouwden we onze eigen software om de boel te draaien. Projecten, klantdata, het hele proces. Daar bovenop draait een set agents: ze doen research, schrijven content, plannen publicaties.
Het belangrijke detail is dat die agents niet los rondzweven. Ze hangen vast aan die software. Als een agent een artikel schrijft over een klant, haalt hij de feiten niet uit het niets: hij trekt ze uit het platform waar de echte projectdata staat. Wat een klant is, wat we voor ze deden, welke afspraken er liggen. Dat zit in het systeem, en de agents lezen daaruit. Systeem praat met systeem.
Dat klinkt als een technisch detail, maar het is in de kern een oud principe dat niets met AI te maken heeft: één plek waar de waarheid staat. Wie z’n klantdata in zeven tools en drie hoofden bewaart, kan geen agent aansluiten. Er is dan geen bron om op aan te sluiten. De winst van een AI-systeem zit dan ook niet in de slimme tekstgenerator op zichzelf. Die kan iedereen aanzetten. De winst zit in de verbinding: de agent die niet hoeft te gokken, omdat hij is aangesloten op de plek waar de waarheid staat. Hoe beter die twee systemen op elkaar aangesloten zijn, hoe minder het systeem verzint en hoe meer het werk uit handen neemt in plaats van werk dat je achteraf moet rechtzetten.
Maar verbinding alleen is niet genoeg
Hier komt de vangst. Een systeem dat goed verbonden is, produceert sneller. En een systeem dat sneller produceert, produceert ook fouten sneller. Sneller dan jij ze kunt lezen.
Toen ik mijn agents opzette, deed ik wat iedereen doet die met AI begint: ik schreef de regels op in de prompt:
Verzin nooit een cijfer. Gebruik alleen bronnen die echt bestaan. Citeer alleen wat je kunt verifiëren.
Het stond er. Letterlijk, in klare taal. En toch produceerde het systeem die nep-McKinsey, die nep-case-study, dat foute verliescijfer. De instructie om niks te verzinnen, stond al in de prompt toen het systeem dingen verzon.
Dat was het moment waarop iets bij me viel. Een prompt is geen regel. Een prompt is een instructie die meestal wordt opgevolgd. En ‘meestal’ is precies het probleem. Onder druk (een lang stuk, een complex onderwerp, een gat in de informatie) vult het model dat gat zelf op en de instructie ‘doe dat niet’ weegt op dat moment minder zwaar dan de drang om een vloeiend, compleet stuk af te leveren. Liever een mooi verzonnen cijfer dan een eerlijk gat.
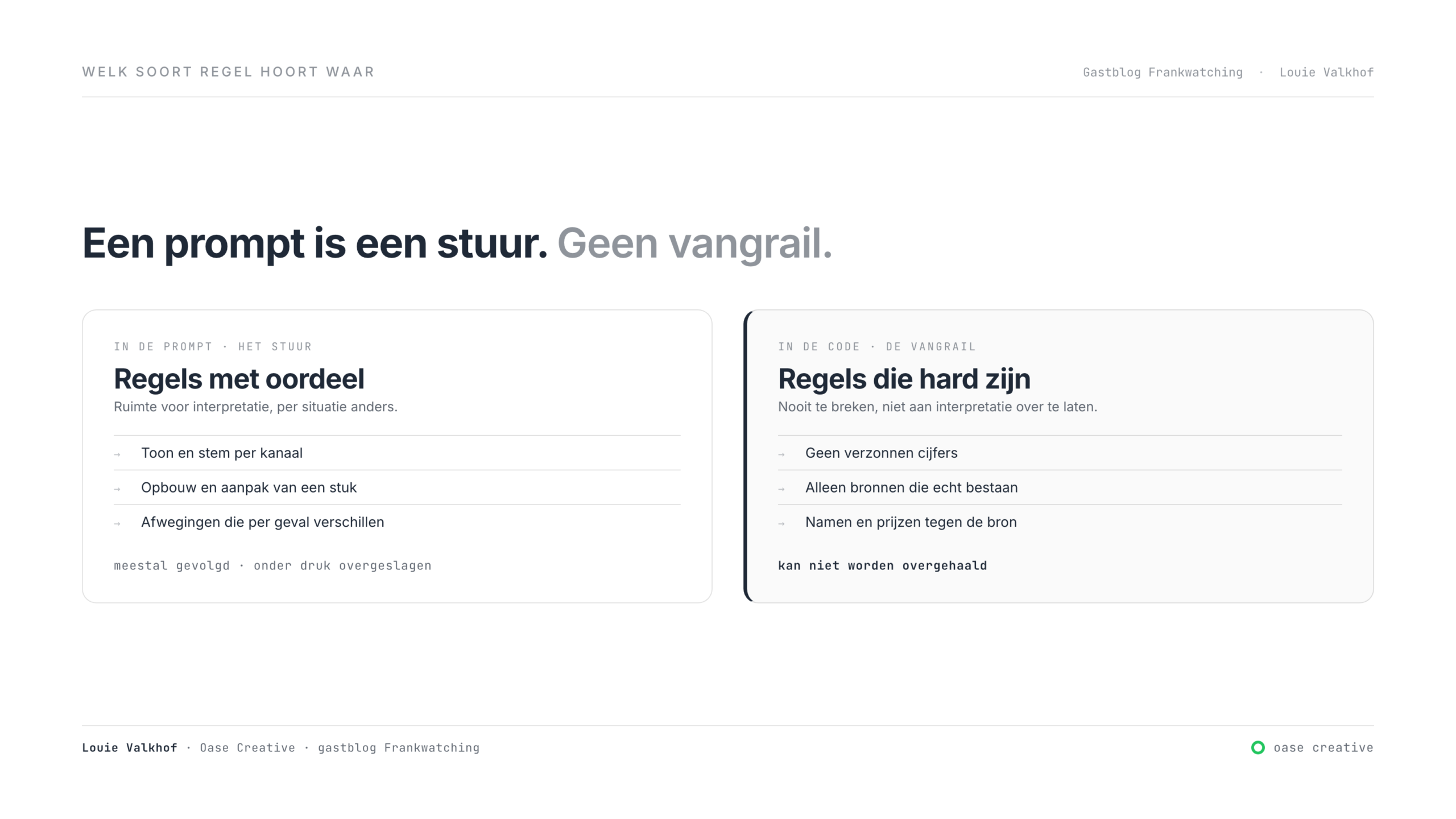
Laat ik daar meteen eerlijk in zijn: dit betekent niet dat prompts waardeloos zijn. Het grootste deel van wat mijn systeem goed doet, komt júist uit prompts: de toon, de opbouw, de aanpak per kanaal, de afwegingen die per situatie verschillen. Prompts zijn het stuur. Maar een stuur is geen vangrail. Het onderscheid dat ik moest leren maken is niet ‘prompts versus code’, maar: welk soort regel leg je waar neer? Regels die ruimte voor interpretatie nodig hebben, horen in de prompt. Regels die nooit gebroken mogen worden, kun je niet toevertrouwen aan iets dat meestal luistert.
Hoe zo’n controlelaag er concreet uitziet
De oplossing was dus niet een betere prompt. Ik heb het geprobeerd: strenger formuleren, voorbeelden geven, in hoofdletters. Het hielp marginaal. Wat wel werkte: de harde regels uit de prompt halen en in code zetten. Een controle die niet kan worden overgehaald.
Concreet doorloopt elk stuk content bij ons drie stappen voordat het in de buurt van publicatie komt:
Stap 1: claims eruit halen
Een check pakt elk getal, elke merknaam en elke bronvermelding uit de tekst. Niet lezen zoals een mens leest, maar mechanisch: alles wat een feitelijke claim is, gaat op een lijstje.
Stap 2: elke claim tegen z’n bron leggen
Per claim controleert het systeem waar hij vandaan zou moeten komen:
- Een extern cijfer met bronvermelding: bestaat die bron, en staat het getal er letterlijk in?
- Een claim over een klant of project: klopt hij met wat er in onze eigen projectdata staat?
- Een feit over ons bedrijf: staat het op de vaste lijst van bevestigde feiten die we bijhouden, met per feit de bron waar het vandaan komt? Niet ‘klinkt dit plausibel’, want dat is weer een oordeel dat je aan het model overlaat. Maar: is dit terug te vinden op de plek waar het vandaan zou moeten komen?
Stap 3: hard falen
Eén claim die niet terug te vinden is, en de publicatie blokkeert. Het stuk gaat terug, met een rapport: deze drie claims konden niet worden geverifieerd. Geen discussie, geen ‘meestal gaat het goed’. Een gefaalde controle publiceert niks.
Het verschil zit niet in hoe slim die controle is. De controle is dom. Hij doet één ding. Het verschil zit erin dat hij niet kan worden overgehaald. Een prompt overtuig je. Een controle die in code zit, niet.
Stap 4: wat door de mechanische controle komt, gaat alsnog langs een mens
En dan is er nog een vierde stap, en die is geen code. Want de check vangt wat objectief fout is: een cijfer dat nergens staat, een naam die verkeerd gespeld is. Maar of een stuk de juiste toon heeft, of het klopt met hoe we ons positioneren, of het vóélt als ons merk? Daar bestaat geen check voor. Dat is oordeel, en oordeel laat zich niet automatiseren. De controlelaag is er niet om de mens te vervangen. Hij is er om te zorgen dat de mens z’n aandacht aan het oordeel kan geven in plaats van aan het naspeuren van elk cijfer.

Dit gaat uiteindelijk niet over AI
Hoe langer ik hiermee werk, hoe duidelijker het wordt dat de echte onderwerpen ouder zijn dan de techniek: één bron van waarheid, kwaliteitscontrole, procesontwerp. Wie verantwoordelijk is voor wat er naar buiten gaat. Dat zijn governance vragen, en die bestonden al toen content nog door drie paar menselijke ogen ging.
Wat AI verandert, is niet wát kwaliteit is, maar het tempo waarop het misgaat als kwaliteit nergens is vastgelegd. Een bureau waar de kwaliteitsregels in hoofden zitten, merkte daar weinig van zolang die hoofden al het werk deden. Zet je er een systeem naast dat tien keer zo veel produceert, dan wordt elke ontbrekende controle ineens zichtbaar, en elke goede controle ineens meer waard. AI vervangt je proces niet. Het versterkt wat er al ligt: een sterk proces wordt sterker, en de gaten in een zwak proces worden groter.
Dat is, denk ik, de nuttigste bril voor wie hierover nadenkt. Niet ‘wat kan AI’, maar: waar staan mijn regels, en wat houdt ze overeind als de productie versnelt?
Van uitvoeren naar verantwoordelijkheid dragen
En dan het deel dat dit verhaal bij elkaar trekt: wat het met jouw rol doet.
Toen die lagen op hun plek stonden (agents verbonden met de data, een controle die de harde fouten tegenhield) veranderde mijn werkdag wezenlijk. Vroeger zat ik in de uitvoering: tekst schrijven, feiten checken, klaarzetten, op de knop drukken. Nu doet het systeem de handelingen, en doe ik iets anders: ik stuur, ik beoordeel, en ik teken ervoor.
Dat laatste is het wezenlijke punt, en het wordt nogal eens gemist in de verhalen over wat AI met werk doet. Het systeem neemt handelingen over. Het neemt geen verantwoordelijkheid over. Elk artikel dat live gaat, gaat onder mijn naam live. Elke fout die erdoorheen glipt, is mijn fout, niet die van het model. De verschuiving is dus niet dat de mens ‘iets minder doet’. De mens verschuift van uitvoeren naar verantwoordelijkheid dragen: je doet minder handelingen, maar je tekent voor meer output dan je ooit zelf had kunnen maken. Dat is een andere baan. En het is precies waarom die controlelaag er moet zijn: je kunt geen verantwoordelijkheid dragen voor werk dat je niet kunt vertrouwen.
De vaardigheid die er straks toe doet is dan ook niet ‘kun je een prompt schrijven’, maar: weet je wat je systemen kunnen, weet je waar je regels liggen, en weet je wat je zelf beslist? En kun je die drie combineren? Wie alleen het eerste kent, bouwt een gimmick. Wie de drie samenbrengt, bouwt iets waar hij met droge ogen z’n handtekening onder durft te zetten.
Wat niet werkt, en wat ik fout deed
Het eerlijke deel, want zonder dat is dit marketing.
Ik dacht een tijdlang dat een goede prompt genoeg was. Dat als je je instructies maar duidelijk en streng genoeg opschreef, het systeem zich eraan zou houden. Dat klopt niet, en ik kwam daar pas achter toen er content met verzonnen statistieken bijna live ging. Niet ‘ik had bijna een typfout’, maar bijna gepubliceerd onder mijn naam, met cijfers van een consultancy die ze nooit had genoemd. In een vak waar je hele waarde op vertrouwen rust.
Een AI-systeem zonder controle eromheen produceert geen rommel die er als rommel uitziet. Het produceert zelfverzekerde, vloeiende, professioneel ogende onzin. Dat is het verraderlijke. Slechte output die er slecht uitziet vang je vanzelf. Slechte output die er goed uitziet glipt erdoorheen, juist omdat je hem vertrouwt.
En de tweede les heb ik hierboven al verklapt: niet elke regel laat zich in code vangen, en de regels die dat niet kunnen (toon, positionering, merkgevoel) zijn niet de restjes. Het is het werk waar ik m’n vrijgekomen tijd aan ben gaan besteden. Wie de controlelaag ziet als een stap richting ‘alles automatiseren’, bouwt het verkeerde ding. Je automatiseert de controle op wat objectief fout is, zodat er méér menselijke aandacht overblijft voor wat alleen een mens kan zien.
Wanneer is dit de investering waard?
Eerlijke vraag, eerlijk antwoord: niet altijd.
Publiceer je twee blogs per maand en leest één persoon alles na, dan is die persoon je controlelaag. Sneller, beter en goedkoper dan alles wat je kunt bouwen. Handmatige controle werkt prima zolang de productie past binnen wat één paar ogen aankan.
De rekensom kantelt op drie momenten.
- De productie groeit voorbij wat je kunt nalezen. Meer stukken, meer kanalen, en nalezen wordt steekproeven.
- Dezelfde fout kan zich op meerdere plekken tegelijk herhalen, omdat één bron-document in tien uitingen terugkomt.
- Het systeem produceert ook wanneer jij er niet bent. ‘S avonds, in het weekend, terwijl jij iets anders doet. Op elk van die momenten verschuift controle van ‘even nalezen’ naar een capaciteitsprobleem, en vanaf daar verdient elke geautomatiseerde check zichzelf terug.
Wie onder die grens zit, heeft geen code nodig. Wel het onderscheid. Want ook een handmatig proces wordt beter als je weet welke regels nooit overgeslagen mogen worden.
Wat je maandag kunt doen
Je hoeft hier geen agents of eigen software voor te bouwen. Het principe staat los van de techniek, en je kunt het sorteren met één beslisboom:
- Is de regel objectief te controleren (een cijfer, een naam, een prijs, een bron)? Dan hoort hij in een controle die hard faalt.
- Is het een oordeel (toon, merk, gevoel, positionering)? Dan hoort hij bij een mens.
Pak je belangrijkste kwaliteitsregel: de fout die je echt nooit naar buiten wil sturen. Voor mij was dat een verzonnen cijfer. Voor jou is het misschien een verkeerde prijs in een offerte, een klantnaam die fout gespeld is, een merk dat niet volgens de huisstijl naar buiten gaat.
Kijk dan per regel naar drie kolommen:
- Wat is de regel
- Waar leeft hij nu
- Waar hoort hij
Staat een nooit-regel in iemands hoofd, een checklist of een prompt? Dan wordt hij overgeslagen. Niet altijd, maar precies op het drukke moment waarop het misgaat. Verhuis hem naar iets dat het werk tegenhoudt in plaats van erop te vertrouwen dat iemand eraan denkt. Dat hoeft geen software te zijn: een verplicht veld dat leeg niet door kan, een tweede paar ogen dat structureel ingebouwd zit in plaats van ‘als er tijd is’, een geautomatiseerde check als je die wél hebt.
Een systeem dat 24/7 draait is het halve verhaal. De andere helft is de controle die maakt dat je het durft te vertrouwen. Niet omdat AI zonder die controle een ramp is, maar omdat productie die versnelt je proces uitvergroot, in beide richtingen. Goede controles worden meer waard. Ontbrekende controles worden duurder. De vraag is alleen wanneer je dat wil ontdekken: vóór je opschaalt, of erna.



Bekijk de korte video's













