
Mens vs. machine: wie wint de marketinguitdaging?


Machine learning was ooit, nog niet zo lang geleden, een contradictio in terminis. Machines, inclusief computers, konden van alles, maar leren? Ho maar! Maar nu is er veel veranderd. Ik leg aan de hand van een fictieve online marketinguitdaging uit hoe machine learning werkt.
Het hele idee van ‘lerende computers’ is onze fantasie gaan beheersen. Als computers leren, hoeveel kunnen ze dan wel niet te weten komen? En wat doen we als ze slimmer worden dan wij?
Voorlopig hebben we vooral nog te maken met computers die zo goed als zelfstandig oplossingen kunnen bedenken voor problemen en modellen kunnen bouwen. Om te begrijpen hoe dat werkt, moet je eigenlijk beginnen bij de basis. En die zit hem in het woord ‘learning’. Want hoe leert een computer nu eigenlijk? En in hoeverre lijkt dat op hoe mensen leren?
Om daar achter te komen, laten we mens en machine het tegen elkaar opnemen in een online marketinguitdaging. Deze is helemaal fictief, maar zeker niet onrealistisch.
De Maarten van Rossem-challenge
Dit is de opdracht. Je wordt door bol.com ingehuurd om het nieuwe boek van Maarten van Rossem gericht te promoten onder de doelgroep. Om dat te doen, moet je eerst bepalen wie de ideale doelgroep is voor zijn nieuwe boek.
In deze battle nemen bol.com-medewerkster Anna en een computer het tegen elkaar op.
1. Anna
Als eerste gaat Anna aan de slag: “Wie zou het nieuwe boek van Maarten van Rossem gaan kopen?”, vraagt Anna zich af. “Waarschijnlijk de mensen die al eerder een boek van hem kochten.” Dus wat doe je dan, als mens: je verzamelt data van klanten uit het systeem die al eens een Van Rossem-boek kochten. Op basis van je intuïtie ga je onderzoeken welke factoren de kans vergroten dat mensen een boek van Maarten van Rossem kopen. Je gaat het rijtje af:
- Ze vermoedt dat het boek vooral voor 50-plussers interessant is. Een analyse van de verkoopcijfers van eerdere boeken van Van Rossem bevestigen dat: 60 procent van de kopers van zijn boeken zijn boven de 50 jaar.
- Zouden mannen vaker tot de doelgroep behoren? Bingo, 72 procent van de kopers is man.
- Ook staat Maarten van Rossem bekend om zijn progressieve opvattingen. Nu staat politieke voorkeur niet in de bol.com-database, maar je weet van de laatste verkiezingsuitslagen dat stedelingen vaker progressief stemmen. En inderdaad: Van Rossem heeft een relatief grotere aanhang onder inwoners van de grootste steden van Nederland.
- Als professor geschiedenis zal de schrijver waarschijnlijk een relatief grote aantrekkingskracht hebben op hoger opgeleiden. De data uit het bol.com-systeem bevestigt dat: met name mensen met een WO-opleiding kopen zijn boeken relatief vaak, gevolgd door hbo’ers.
- Het laatste vermoeden dat Anna toetst, is of bol.com-klanten met een bovengemiddelde interesse in geschiedenisboeken ook vaker een boek van Van Rossem kopen. Dat blijkt niet zo te zijn: het aantal geschiedenisboeken dat klanten ooit hebben gekocht, verhoogt niet de kans dat ze het boek van Van Rossem kopen.
Het onderzoek van Anna heeft vier relevante input-variabelen opgeleverd voor haar model om te voorspellen of klanten geïnteresseerd zijn in Van Rossem’s nieuwe boek: leeftijd, geslacht, woonplaats en opleidingsniveau. Anna’s advies: een campagne zou zich vooral moeten richten op mannen boven de 50 jaar, in de vijf grote steden van Nederland en met een universitaire opleiding.
2. Computer
Nu is het de beurt aan de machine: ook de computer zal gebruik maken van historische data om tot een model te komen. Net als Anna zal hij zo veel mogelijk data verzamelen over klanten die ooit een boek van Maarten van Rossem hebben besteld en een profiel schetsen. Maar deze analyse verschilt op verschillende onderdelen van die van Anna:
Leeftijd
Leeftijd speelt zeker een rol, maar de leeftijdsgrens van 50 jaar die de mens heeft getrokken, is arbitrair. De scheidslijn van 42 jaar blijkt een betere voorspellende waarde op te leveren.
De vijf grootste steden van Nederland
Het klopt inderdaad dat inwoners van de vijf grootste steden van Nederland vaker een Van Rossem kopen, maar dat geldt ook voor inwoners van Nijmegen, Wageningen, Maastricht, Tilburg, Groningen en Delft. Kortom: in universiteitssteden zijn inwoners vaker fan van de professor.
Er blijkt dan ook een correlatie te zijn tussen ‘opleidingsniveau’ en ‘inwoner van een grote stad’. Als computer houd je in je model rekening met die onderlinge samenhang en combineer je de twee factoren om gezamenlijk tot de beste voorspellende waarde te komen.
Koopintentie
Een specifiek segment van de doelgroep blijkt ook een bovengemiddeld hoge koopintentie te hebben: vrouwen tussen de 30 en 40 jaar in kleine dorpen in de Randstad. Wat blijkt: Van Rossem heeft vorig jaar een tour gemaakt langs vrouwenleesclubjes en daar lezingen gegeven. De leden zijn nog steeds bovengemiddeld geïnteresseerd in zijn publicaties.
De Slimste Mens
Iets wat je als mens misschien ook niet zag aankomen: mensen die vaker een bordspel kopen op bol.com, zijn ook eerder geneigd een boek van Van Rossem aan te schaffen. De missing link tussen die twee variabelen is natuurlijk De Slimste Mens. Spelletjesfanaten kennen hem als jurylid bij dat programma en gaan eerder naar bol.com om zijn boeken te kopen.
De knikkerbaan
Als de computer al deze variabelen heeft bepaald, is het tijd om een model te bouwen. In dit model zitten vijf input-variabelen: leeftijd, woonplaats (universiteitsstad ja/nee), opleidingsniveau, geslacht, spelletjeskoper (ja/nee) en één output-variabele: koopkans (in procent). Met machine learning is het mogelijk om de optimale beslisboom te maken, die lijkt op een omgekeerde trechter: je test achtereenvolgens op verschillende variabelen. Dit wordt ook wel een knikkerbaan genoemd:
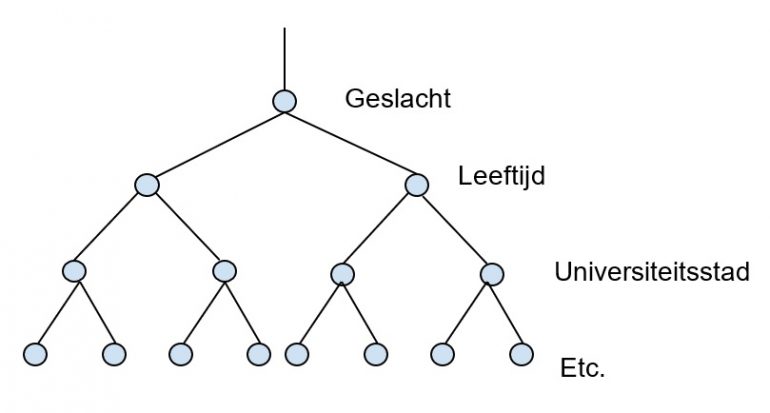
Hoe een computer in dit voorbeeld leert, dat zit hem dus vooral in het feit dat hij steeds blijft zoeken naar het optimale model. Nu lag de scheidslijn qua leeftijd op 42 jaar, maar als dat in de loop der tijd verandert naar 39 of 45, dan past het systeem het model daar op aan. Is dit de enige vorm van machine learning? Nee, het is een specifiek geval waarin kunstmatige intelligentie tot het optimale model komt op basis van patroonherkenning.
Waarin is de computer beter dan de mens?
Op welke onderdelen wordt Anna in dit voorbeeld verslagen door de computer? Allereerst gaat de computer nauwkeuriger en systematischer te werk in het ontdekken van input-variabelen. Omdat computers meer data kunnen verwerken dan mensen, hoeven ze niet op hun intuïtie af te gaan en kunnen ze verbanden ontdekken die mensen niet zouden verwachten. Bijvoorbeeld die tussen de aanschaf van gezelschapsspellen en de kans dat een klant dan ook een boek van Maarten van Rossem koopt.
Ook kun je met behulp van machine learning de waarde van input-variabelen sneller en nauwkeuriger bepalen. Waar ligt de ideale leeftijdsgrens om te voorspellen wie een Van Rossem-boek koopt? Is dat 50, 36, of 42? Computers kunnen deze analyse niet beter, maar wel veel sneller uitvoeren dan mensen.
Dat brengt ons bij het belangrijkste voordeel van computers ten opzichte van mensen: we hebben het hier slechts over één boek, maar bol.com wil elke week van honderden boeken weten wat het ideale klantprofiel is. Zet daar maar eens een stagiaire op.
Mens vs. computer?
Uiteindelijk levert een computer een beter model, omdat artificial intelligence (AI) beter in staat is om variabelen te identificeren, deze op waarde te schatten (is de grens 50 of toch 42 jaar?) en hun onderlinge verband in kaart te brengen. Dat levert een model op dat bijvoorbeeld met 75 procent zekerheid kan voorspellen of iemand een boek zal kopen, terwijl het door de mens gemaakte model een slagingskans heeft van 40 procent.
Om nog maar te zwijgen over de hoeveelheid aan modellen die een computer op een dag kan genereren…



Bekijk de korte video's










8 strategische tips om slimmer te werken met Copilot
Meer wetenEU AI Act: wat jij vóór 2 augustus moet regelen
Meer wetenSEO & GEO met AI
Meer wetenCanva met AI
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenDe nieuwe SEO- & GEO-spelregels: scoren in Google én AI-search
Meer wetenAI Update (archief)
Meer wetenSEO-copywriting met AI
Meer wetenSEO & GEO met AI
Meer wetenCommunicatie & AI
Meer wetenOp zoek naar nog meer kennis?
-
Zo ga je als marketeer aan de slag met Claude Cowork
-
Nederland scoort hoog op digitale overheid, maar hapert waar het telt
-
Zo zorg je dat kijkers niet wegscrollen bij je YouTube Shorts
-
De 7 grootste mythes over presenteren om eindelijk te ontkrachten
-
AI neemt de productie over en juist daarom wint het echte verhaal

