
De nieuwe Google Search Console: dit kun je ermee

Sinds januari van dit jaar heeft iedereen toegang tot de bètaversie van de nieuwe Google Search Console. Op het eerste gezicht zijn vooral de uitstraling en gebruiksvriendelijkheid erop vooruitgegaan, maar onder de oppervlakte verbergt zich een nieuwe bron aan SEO-gerelateerde data. Zo is er meer aandacht voor problemen zoals index bloat, crawl budget en zelfs duplicate content. In deze post een kort verslag van de ontwikkelingen en een aantal concrete aanknopingspunten waar je direct mee aan de slag kunt.
Voor menig SEO-specialist is Google Search Console een belangrijk instrument tijdens de dagelijkse bezigheden. De tool geeft veel informatie over hoe bezoekers jouw website vinden. Bovendien geeft Search Console uniek inzicht in hoe de zoekmachine jouw website crawlt. Met alle gebruikersfeedback verbetert Google de mogelijkheden van de tool en worden Search Console-rapporten stapsgewijs uitgerold. Om die reden zijn er op dit moment nog maar twee rapporten beschikbaar, over prestaties en indexdekking.
Prestaties
Het zoekanalyserapport staat in de nieuwe Search Console bekend als ‘prestaties’. Een van de grootste ontwikkelingen in de bètaversie is dat dit rapport nu data van de afgelopen 16 maanden laat zien. Dat was 90 dagen, een flinke beperking voor gebruikers. De uitbreiding maakt het nu bijvoorbeeld mogelijk om maandprestaties met het voorgaande jaar te vergelijken.
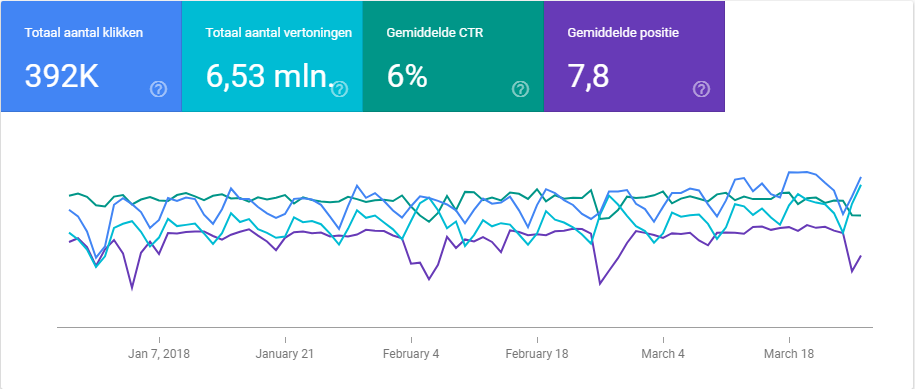
Wat vooral opvalt is het nieuwe uiterlijk van dit rapport. Dat oogt een stuk fraaier en de gebruiksvriendelijkheid is geoptimaliseerd.
Handig: Zo beïnvloed je het crawlen en indexeren van je website
Wat betreft nieuwe functionaliteiten: deze zijn vooral in de details te vinden. Zo is het nu mogelijk om filters in te stellen op clicks, vertoningen, CTR en positie. Hiermee zou je bijvoorbeeld alle zoekwoorden die lager dan positie 10 scoren, uit je rapport kunnen filteren.
Indexdekking
Het nieuwe rapport ‘indexdekking’ is een combinatie van de oude rapporten ‘indexeringsstatus’, ‘crawlfouten’ en ‘sitemaps’. Deze omvatten stuk voor stuk specifieke URL’s van je website, waardoor een combinatie van de 3 het werken met Google Search Console vergemakkelijkt. Bovendien is ‘indexdekking’ nog verder uitgebreid met veel nieuwe informatie over de indexering van je website in Google.
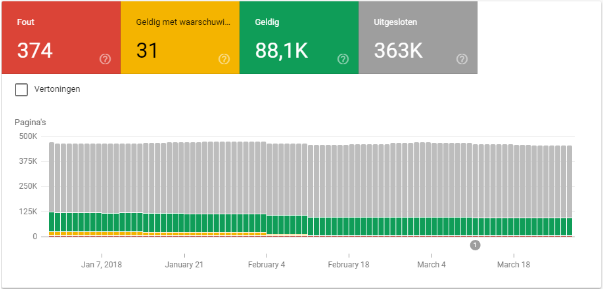
De 4 gekleurde blokken aan de bovenkant van het rapport (zie afbeelding hierboven), staan voor de mogelijke paginastatussen waarop gefilterd kan worden: ‘fout’, ‘geldig met waarschuwing’, ‘geldig’ en ‘uitgesloten’. Voorheen toonde Google alleen de crawlfouten van specifieke URL’s. Onduidelijkheid over waarom de zoekmachine een URL wel of niet indexeert, is vanaf nu dus verleden tijd.
Binnen elk van deze statussen kun je nog specifiekere redenen vinden achter de betreffende URL-status (zie de opsommingen hieronder). Deze zijn flink uitgebreid in de bètaversie van de tool en enorm zinvol voor je optimalisaties.
Oud:
- Ingediende URL niet gevonden (404)
- Niet gevonden (404)
- Serverfouten (5xx)
- Ingediende URL is een soft 404
- Ingediende URL geblokkeerd door robots.txt
Nieuw:
- Probleem met crawlen voor ingediende URL
- Fout met omleiding
- Ingediende URL gemarkeerd als noindex
- Geïndexeerd, maar geblokkeerd door robots.txt
- Ingediend en geïndexeerd
- Geïndexeerd, niet ingediend in sitemap
- Crawlafwijking
- Pagina met omleiding
- Geblokkeerd door robots.txt
- Alternatieve pagina met correcte canonieke tag
- Google heeft een andere canonieke pagina gekozen dan de gebruiker
- Gecrawld – momenteel niet geïndexeerd
- Uitgesloten door tag noindex
- Gevonden – momenteel niet geïndexeerd
- Dubbele pagina zonder canonieke tag
Een handig extraatje is dat een overzicht van URL’s die onder een bepaalde fout vallen, eenvoudig gedeeld kan worden met iedereen met een Google-account.
Validatie
Een interessante nieuwe feature van het indexdekkingrapport is de validatiefunctie. Waar je voorheen een crawlfout alleen als ‘gecorrigeerd’ kon markeren, kun je nu per type crawlfout een validatie aanvragen.
 Als je een validatie aanvraagt voor een bepaald type crawlfout, zal Google de desbetreffende URL’s opnieuw gaan crawlen. Vervolgens krijg je een overzicht van welke URL’s behandeld zullen worden en welke hiervan de validatie niet zijn doorgekomen. Via de mail word je hiervan op de hoogte gehouden.
Als je een validatie aanvraagt voor een bepaald type crawlfout, zal Google de desbetreffende URL’s opnieuw gaan crawlen. Vervolgens krijg je een overzicht van welke URL’s behandeld zullen worden en welke hiervan de validatie niet zijn doorgekomen. Via de mail word je hiervan op de hoogte gehouden.
Top! Maar wat kan ik ermee?
Het beschikken over twee nieuwe, flink uitgebreide rapporten in Google Search Console is superhandig. Maar wat kun je er nu concreet mee? Hieronder vind je een aantal tips om mee te beginnen.
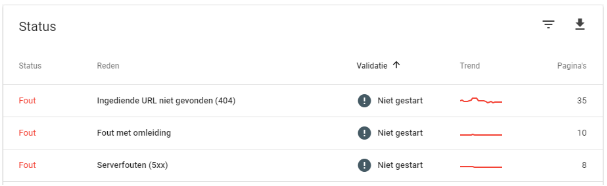 Index bloat
Index bloat
Met name grotere websites en webshops zullen wel eens last hebben van index bloat. Dit houdt in dat het aantal geïndexeerde pagina’s veel hoger ligt dan het aantal waardevolle pagina’s op de website. Google geeft dus veel aandacht aan pagina’s die niet relevant zijn voor de vindbaarheid, en minder aandacht aan belangrijke pagina’s.
De Search Console Bèta bevat een aantal rapporten die kunnen helpen bij het tegengaan van index bloat. Deze kun je vinden onder de status ‘geldig’ in het indexdekkingrapport.
- Geïndexeerd, niet ingediend in sitemap. De vuistregel is dat alle belangrijke pagina’s – en dus alle pagina’s die je geïndexeerd zou willen hebben – in de sitemap staan. Ga eens na welke pagina’s worden geïndexeerd zonder dat ze in de sitemap staan, en of deze wel waarde hebben voor de index. Is dit niet het geval? Geef ze dan een meta noindex-tag.
- Geïndexeerd, maar geblokkeerd door de robots.txt. Het is een veelvoorkomende misvatting dat, zodra een pagina is opgenomen in de robots.txt, deze niet meer gecrawld en geïndexeerd kan worden. Alleen een meta noindex-tag kan hiervoor zorgen.
Crawl budget
Naast index bloat is er nog een belangrijke factor om rekening mee te houden bij het optimaliseren van crawlability: crawl budget. Kort gezegd is dit de hoeveelheid aandacht die Google aan een website wil schenken, uitgedrukt in de gemiddelde hoeveelheid pagina’s die het per dag zal crawlen. In de oude versie van Search Console is een benadering hiervan te vinden in het rapport ‘crawlstatistieken’.
Ondanks dat de bèta nog geen statistieken bevat die een indicatie van het crawlbudget bieden, kan een aantal rapporten wel helpen bij het verbeteren van het budget. Deze kun je vinden in het indexdekkingrapport onder de status ‘Fout’:
- Fout met omleiding. Zeker bij de grotere websites/webshops zullen redirects zich al snel opstapelen, wat tot redirect chains kan leiden en een strop kan zijn voor het crawlbudget. Gelukkig zijn ze nu eenvoudig te vinden via dit rapport, zonder dat er een volledige websitecrawl voor nodig is.
- Niet gevonden (404). Pagina’s die niet meer beschikbaar zijn en de http-status 404 hebben gekregen, zullen geregeld opnieuw gecrawld worden om te controleren of ze weer actief zijn. Een verspilling van het crawlbudget. Gebruik liever 301-redirects om bezoekers naar nieuwe relevante pagina’s te leiden, of de 410-foutmelding om aan te geven dat een pagina nooit meer terug zal komen.
Duplicate content
Naar mijn idee is duplicate content een van de grootste issues voor grotere websites. Met name webshops zullen veel soortgelijke pagina’s hebben. Het vinden van pagina’s die ook echt dubbel zijn, is hierdoor moeilijk.
In een heel gebruiksvriendelijk overzicht (indexdekkingsrapport > status ‘uitgesloten’) geeft Google nu aan welke pagina’s als dubbel worden gezien. Hierdoor kunnen deze heel gericht worden aangepakt.
- Dubbele pagina’s zonder canonieke tag. Een canonieke tag is een eenvoudige manier om aan te geven dat een pagina dezelfde content bevat als een andere. De tag maakt duidelijk welke van de twee pagina’s het belangrijkste is voor de index.
In feite zegt Google met dit rapport dat het twee pagina’s heeft gevonden die sterk op elkaar lijken, zonder dat is aangegeven welke geïndexeerd mag worden. Dit zou je met een canonieke tag op een van de twee pagina’s al kunnen oplossen.
Bèta blijft bèta
Voor een bètaversie zijn de twee beschikbare rapporten in Google Search Console een hele verbetering. Bèta blijft echter wel bèta, wat betekent dat kinderziektes niet uitgesloten zijn. Zo verschilt het aantal geïndexeerde pagina’s in de bèta ten opzichte van de oude versie. Maar het betekent ook dat we in de toekomst meer verbeterde rapporten mogen verwachten.
Hopelijk kun je met bovenstaande punten toch al gaan profiteren van een (naar mijn mening) uitstekende nieuwe Google Search Console. Heb jij nog nieuwe functies gevonden in de bètaversie? Laat het mij vooral weten via de reacties!



Bekijk de korte video's








Napkin AI: de tool die jouw tekst omzet naar ijzersterke visuals
Meer wetenAdverteren op Instagram & Facebook (Meta)
Meer wetenSocial media strategie
Meer wetenAI Update (archief)
Meer wetenSEO & GEO met AI
Meer wetenAI Marketing
Meer wetenAI Marketing
Meer wetenSEO & GEO met AI
Meer wetenOp zoek naar nog meer kennis?
-
AI gaat de carrièreladder drastisch veranderen
-
6 AI-prompts die je agile marketingproces direct verbeteren
-
De Wtta treft niet alleen uitzendbureaus: dit moet elke digitale agency weten
-
Waarom ANWB de hoogste AI-reputatie heeft & wat marketeers hiervan leren
-
Hoe veilig is jouw website écht? Een AI-hacker is in 10 minuten binnen




