ChatGPT & het Nederlands: hoe scoren AI-tools op ’taal’?


Je kunt in het Nederlands met ChatGPT praten en de tool geeft ook keurig in het Nederlands een antwoord terug. Vaak verrassend goed! Maar, soms klopt het toch niet helemaal… Je merkt dan dat het model van ChatGPT in het Engels ‘denkt’. Ik vroeg me af: hoe goed is ChatGPT met de Nederlandse taal? En is het eigenlijk een probleem dat AI-tools op de Engelse taal gebaseerd zijn? Zijn er al Nederlandstalige initiatieven?
Kun je ChatGPT in het Nederlands gebruiken?
Laten we beginnen met een veelgestelde vraag: kun je in het Nederlands praten met ChatGPT? Het antwoord daarop is ‘ja’. Als je in het Nederlands een prompt (vraag) stelt aan de tool, antwoordt het in het Nederlands terug. Soms helpt het wel om in je prompt aan te geven dat je een Nederlands antwoord verlangt. En sinds kort kun je in Custom Instructions ook aangeven dat je altijd de voorkeur hebt voor deze taal.
Maar soms gaat het mis
Maar in de antwoorden van ChatGPT kun je weleens merken dat het vertaald is uit het Engels. Als ik bijvoorbeeld de tool laat brainstormen over titels bij een artikel, heeft elk woord in een titel een hoofdletter (dat is een Engelse gewoonte). Maar ook de toon van de titels is soms erg over-the-top clickbaiterig Amerikaans. Hier een paar voorbeelden:
- Superchargeer je online aanwezigheid met ChatGPT: Meester je SEO & copywriting!
- Enshittification: De Stille Moordenaar van Digitale Platforms
- SEO Geheimen Onthuld: Begrijp de Zoekintenties van Je Doelgroep
Bij moppen en raadsels gaat het soms ook mis. Voor een kinderfeestje maakte ik een paardenquiz en ik vroeg ChatGPT om hulp. Bij een paar vragen kreeg ik bijzondere antwoorden, waaronder deze:
- Hoe heten de hoefijzers van paarden? Antwoord: Horseshoes
Dit zijn natuurlijk maar een paar voorbeelden, ik krijg veel vaker geschikte antwoorden van ChatGPT. Maar juist bij dit soort gevallen merk ik dat ChatGPT Engels ‘denkt’ en de antwoorden naar het Nederlands vertaalt.
Hoe zit het met dat Engelse denken? En is het een probleem voor het gebruik van AI-tools als Engels niet je moedertaal is? Ik ging erover in gesprek met Joachim de Greeff, Senior Consultant AI and Robotics bij TNO.
Trainingsdata van AI-tools: voornamelijk Engels
De meeste large language models (AI die zijn getraind om menselijke taal te begrijpen, te genereren en te manipuleren) zijn veruit het best getraind op de Engelse taal. Bij OpenAI (eigenaar van ChatGPT) en veel andere AI-bedrijven is bijvoorbeeld gebruikgemaakt van de database van Common Crawl, dat het web doorzoekt. Doordat op het internet de meest gebruikte taal Engels is (daarna volgen Spaans en Chinees), is het dus ook logisch dat de large language models (LLM’s) daar het meest op getraind zijn.
Tijdens het crawlen worden ook Nederlandse en Vlaamse teksten meegenomen, al maakt dat een kleiner deel uit van het internet. En de gebruikte websites zijn nogal willekeurig. Uit onderzoek van De Groene Amsterdammer en Data School blijkt bijvoorbeeld dat in de mC4-dataset van Common Crawl veruit de meeste Nederlandstalige teksten komen van Docplayer.nl, Tripadvisor, Uitspraken.rechtspraak.nl, NRC en Tweakers. Maar ook 12,5 miljoen woorden van Frankwatching.com vonden hun weg in deze database.
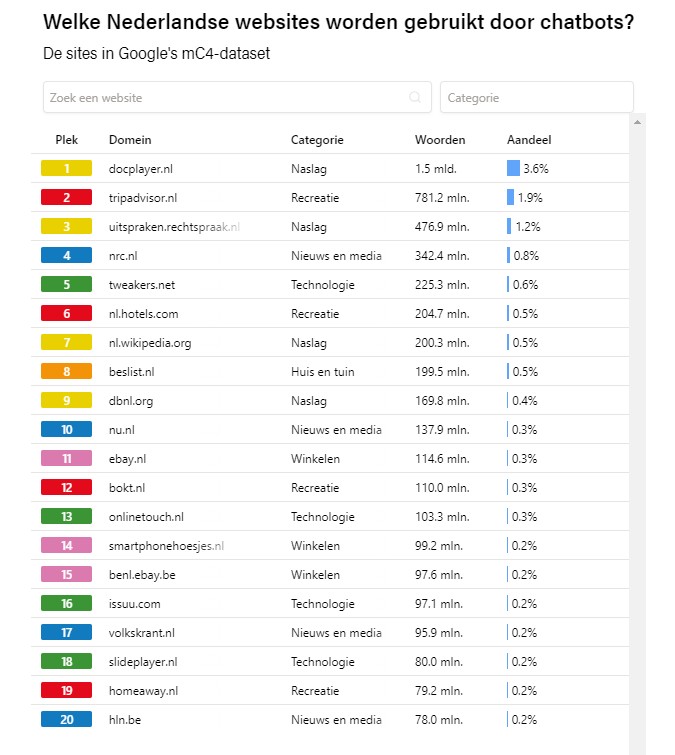
De top 20 Nederlandse websites in de mC4-dataset. Screenshot van De Groene Amsterdammer.
Overigens, niet alle bedrijven zijn transparant over welke gegevens precies zijn gebruikt om hun LLM’s mee te trainen. En wat er in de mC4-dataset staat, is niet allemaal legaal. Dit brengt natuurlijk issues met zich mee, zoals een aantal rechtszaken over auteursrechten nu al laten zien.
Focus van AI-ontwikkelaars ligt ook op het Engels
Een andere reden waarom het Engels de boventoon voert in AI-tools is omdat de grote techbedrijven nou eenmaal daar hun focus op hebben vanwege de wereldwijde (online) dominantie van de taal. “De grote innovaties voor AI zitten bovendien tegenwoordig minder bij universiteiten en meer bij Big Tech”, stelt Joachim. Met het Engels wordt een grotere doelgroep bediend én meer geld verdiend. Daardoor worden kleinere talen zoals het Nederlands meer bijzaak.
Dit heeft impact op de innovaties en optimalisaties voor AI in kleinere talen. En denk daarbij niet alleen aan het Nederlands, maar ook aan nóg kleinere talen of zelfs dialecten, zoals het West-Fries.
De grote innovaties voor AI zitten tegenwoordig minder bij universiteiten en meer bij Big Tech. – Joachim de Greeff
De nadelen van Engelstalige AI
Nu vraag je je misschien af: ach, ChatGPT werkt al best goed voor mij, is het nou zo erg dat het minder goed getraind is op het Nederlands? Deze ontwikkelingen hebben toch wel enkele nadelige gevolgen. Zo lieten mijn voorbeelden eerder al zien dat een tool als ChatGPT in het Nederlands minder accurate antwoorden kan geven en daardoor iets slechter presteert dan in het Engels. Je hebt ook het risico op het genereren van eenheidsworst en ik mis soms de nuances in het taalgebruik. Een Nederlander communiceert nou eenmaal anders dan een Amerikaan.
Maar kijk ook naar het toekomstige gebruik van AI-assistenten, zoals CoPilot van Microsoft. In dit artikel op The Rest of World stelt Russel Brandom (tech editor) dat ons werk gaat ‘achterlopen’ op met name Engelstalige landen, doordat de nieuwste features van tools altijd eerst in het Engels worden uitgebracht.
Tijd voor Nederlandstalige AI dus?
Er is nog een ander nadeel: het is niet wenselijk dat Europa afhankelijk is van de tools van Big Tech uit de VS of China. Soevereine AI is daarom een belangrijk thema. In mijn gesprek met Joachim de Greeff kwamen al enkele interessante AI-initiatieven naar voren. Onlangs kwam in het nieuws dat TNO een subsidie ontvangt voor GPT-NL, dat de onderzoeksorganisatie samen met het Nederlands Forensisch Instituut en SURF gaat ontwikkelen.
Ook gaat er een Europees project genaamd TrustLLM starten waarin 6 landen uit dezelfde taalfamilie – Nederland, Duitsland, Denemarken, Noorwegen, IJsland en Zweden – samenwerken voor de ontwikkeling van een AI-model. Door de nationale taal te overstijgen, krijg je een grotere dataset waar de AI op getraind kan worden. En daardoor kan de AI hopelijk ook beter presteren.
AI-modellen op basis van Europese talen en waarden, dat klinkt goed! Maar Joachim geeft aan dat deze projecten qua investeringen niet kunnen tippen aan die in AI in de VS en China. Ze bieden wel de kans om ervaring op te doen. En de modellen kunnen hopelijk breed ingezet worden.
Kantelpunt: van kwantitatief naar kwalitatief
Ik vroeg me nog af: is er eigenlijk een minimum hoeveelheid data nodig om AI te trainen? Joachim geeft aan dat er momenteel een kantelpunt is. Voorheen was het idee dat hoe meer data je hebt, hoe beter de AI getraind wordt. Maar die data kan vervuild zijn met allerlei gegevens die je er eigenlijk niet in wil hebben. ‘Garbage in, garbage out’ is een bekende uitspraak in de AI-wereld. Als je AI traint op kwalitatief slechte data, dan zal het ook slecht presteren. Wel kun je daarna – meestal met menselijke moderatie – de AI verder trainen om de performance te verbeteren.
Daarnaast is de Europese AI Act een belangrijke driver voor aanpassingen. Deze wetgeving gaat eisen stellen op het gebied van transparantie, ethiek, traceerbaarheid en intellectuele eigendomsrechten. En daardoor gaat het ook eisen stellen aan de gebruikte data.
Dus van het puur gebruiken van willekeurige data uit Common Crawl, wordt nu onderzocht hoe je kwalitatief hoogstaande gegevens kunt gebruiken. De uitdaging is: hoe cureer je die gegevens? Hoe bepaal je wat kwaliteit is?
Misschien biedt dit wel hoop voor de kleinere talen om in de toekomst net zo goed te werken in AI als in het Engels.
Nederlandse AI: er is hoop
Zelfs met de huidige Engelse AI-tools kun je al veel handige dingen doen. Wellicht hebben we ook geluk dat het Nederlands en Engels met elkaar verwant zijn en de tools daardoor ook voor ons al best goed werken. Maar het is toch een nadeel om puur en alleen afhankelijk te zijn van grote, commerciële bedrijven en daarbij achterlopen omdat je geen Engels (of Chinees of Spaans) spreekt.
Er zijn gelukkig wel een aantal hoopvolle Europese initiatieven onderweg, samen met de AI Act. Maar zolang het grote geld nog omgaat in Big Tech, is het de vraag hoe lang het duurt voordat we soevereine, kwalitatief vergelijkbare AI kunnen gebruiken.



Bekijk de korte video's











